

Web scraping é o processo de coleta automática de dados de sites para fins como análise de dados ou ajuste fino de modelos de IA.
Python é uma escolha popular para web scraping devido à sua extensa variedade de bibliotecas de scraping, incluindo lxml, que é usada para analisar documentos XML e HTML. O lxml estende os recursos do Python com uma API Python para as bibliotecas C rápidas libxml2 e libxslt. Ele também se integra com ElementTree, a estrutura de dados hierárquica do Python para árvores XML/HTML, tornando o lxml uma ferramenta preferida para captura de dados na web eficiente e confiável.
Neste tutorial, você aprenderá a usar o lxml para extrair dados da web.
Soluções de dados brilhantes como a alternativa perfeita
Quando se trata de web scraping, usar lxml com Python é uma abordagem poderosa, mas pode ser demorada e cara, especialmente ao lidar com sites complexos ou grandes volumes de dados. A Bright Data oferece uma alternativa eficiente com seus conjuntos de dados prontos para uso e APIs do Web Scraper. Essas soluções reduzem significativamente o tempo e o custo envolvidos na coleta de dados, fornecendo dados pré-coletados de mais de 100 domínios e APIs de raspagem fáceis de integrar.
Com a Bright Data, você pode contornar os desafios técnicos da coleta manual, permitindo que você se concentre na análise dos dados em vez de recuperá-los. Se você precisa de conjuntos de dados personalizados para seus requisitos específicos ou de APIs que lidam com o gerenciamento de proxy e com a solução de CAPTCHA, as ferramentas da Bright Data oferecem uma solução simplificada e econômica para todas as suas necessidades de web scraping.
Usando lxml para captura de dados na web em Python
Na web, dados estruturados e hierárquicos podem ser representados em dois formatos: HTML e XML:
- XML é uma estrutura básica que não vem com tags e estilos predefinidos. O programador cria a estrutura definindo suas próprias tags. O objetivo principal da tag é criar uma estrutura de dados padrão que possa ser entendida entre diferentes sistemas.
- HTML é uma linguagem de marcação web com tags predefinidas. Essas tags vêm com algumas propriedades de estilo, como
font-sizeem tags<h1>oudisplaypara tags<img />. A principal função do HTML é estruturar páginas da web de forma eficaz.
lxml funciona com documentos HTML e XML.
Pré-requisitos
Antes de começar a extrair dados com lxml, você precisa instalar algumas bibliotecas em sua máquina:
pip install lxml requests cssselect
Esse comando instala o seguinte:
- lxml para analisar XML e HTML
- requests para buscar páginas da web
- cssselect, que usa seletores CSS para extrair elementos HTML
Analisando conteúdo HTML estático
Dois tipos principais de conteúdo da web podem ser copiados: estático e dinâmico. O conteúdo estático é incorporado ao documento HTML quando a página da web é carregada inicialmente, facilitando a extração. Por outro lado, o conteúdo dinâmico é carregado continuamente ou acionado pelo JavaScript após o carregamento inicial da página. A extração de dados de conteúdo dinâmico exige que a função de extração seja cronometrada para ser executada somente depois que o conteúdo estiver disponível no navegador.
Neste tutorial, você começa copiando o site Books to Scrape, que tem conteúdo HTML estático criado para fins de teste. Você extrai os títulos e preços dos livros e salva essas informações como um arquivo JSON.
Para começar, use as Dev Tools (Ferramentas do Desenvolvedor) do seu navegador para identificar os elementos HTML relevantes. Abra Dev Tools clicando com o botão direito do mouse na página da web e selecionando a opção Inspecionar. Se você estiver no Chrome, pode pressionar F12 para acessar este menu:
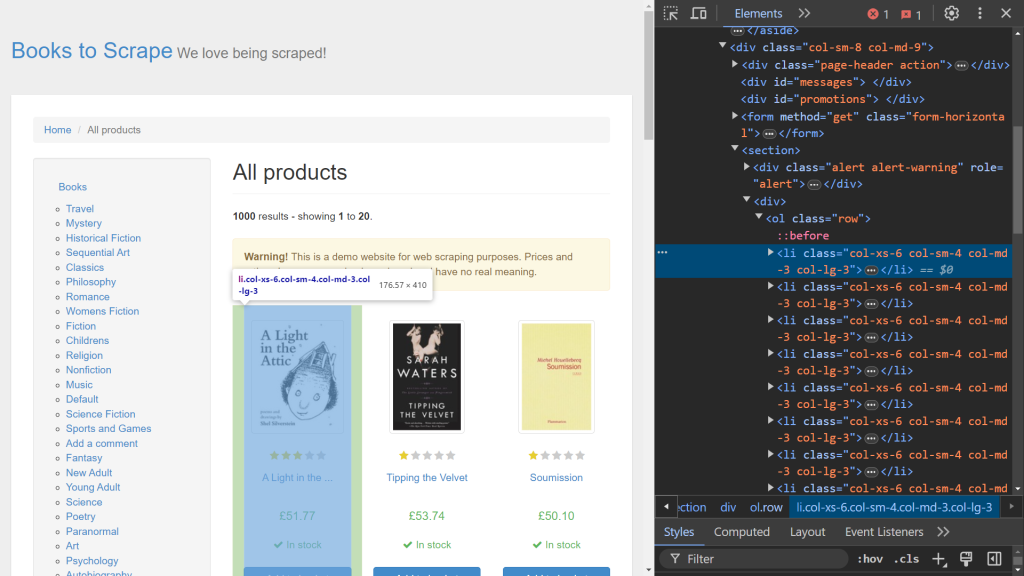
O lado direito da tela exibe o código responsável pela renderização da página. Para localizar o elemento HTML específico que manipula os dados de cada livro, pesquise o código usando a opção de passar o mouse para selecionar (a seta no canto superior esquerdo da tela):
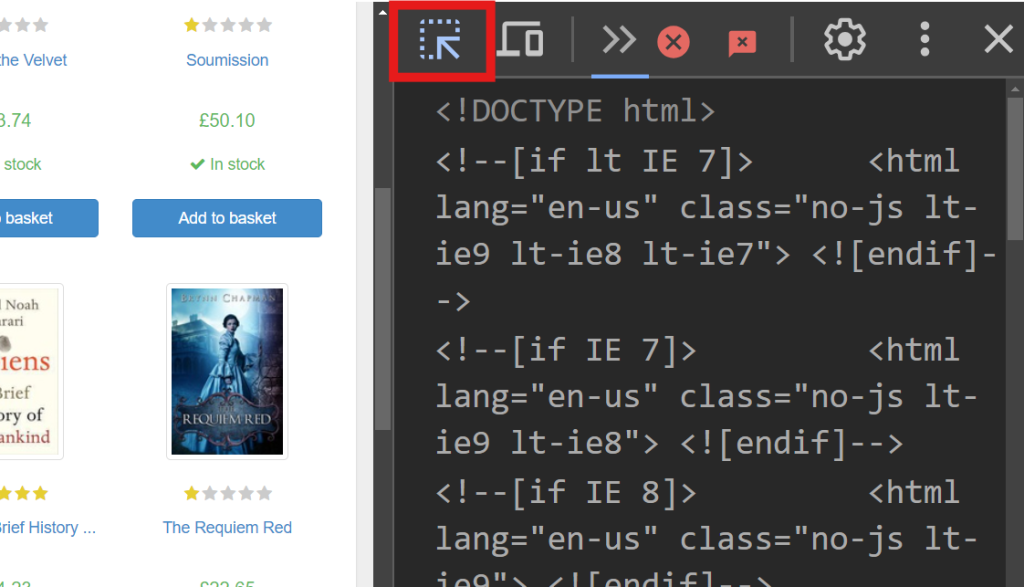
Em Dev Tools, você deve ver o seguinte trecho de código:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>
Neste trecho, cada livro está contido em uma tag <article> rotulada com a classe product_pod. Você direciona esse elemento para extrair os dados. Crie um novo arquivo chamado static_scrape.py e adicione o seguinte código:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
Esse código importa as bibliotecas necessárias e define uma variável URL. Ele usa requests.get() para buscar o conteúdo HTML estático da página da web enviando uma solicitação GET para o URL especificado. Em seguida, o código HTML é recuperado usando o atributo text da resposta.
Depois que o conteúdo HTML for obtido, sua próxima etapa é analisá-lo usando lxml e extrair os dados necessários. O lxml oferece dois métodos de extração: seletores XPath e CSS. Neste exemplo, você usa o XPath para recuperar o título do livro e os seletores CSS para obter o preço do livro.
Anexe seu script com o seguinte código:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
Esse código inicializa a variável parsed usando html.fromstring(content), que analisa o conteúdo HTML em uma estrutura de árvore hierárquica. A variável all_books usa um seletor XPath para recuperar todas as tags <article> tags com a classe product_pod da página da web. Essa sintaxe é especificamente válida para expressões XPath.
Em seguida, adicione o seguinte ao seu script para percorrer cada livro em all_books e extrair dados deles:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
A variável book_title é definida usando um seletor XPath que recupera o atributo de um atributo title de uma tag <a> dentro de uma tag <h3>. O ponto (.) no início da expressão XPath especifica começar a pesquisar a partir da tag <article> em vez do ponto de partida padrão. A próxima linha usa o método cssselect para extrair o preço de uma tag <p> com a classe price_color. Como cssselect retorna uma lista, a indexação ([0]) acessa o primeiro elemento e text_content() recupera o texto dentro do elemento. Cada título extraído e cada par de preços é então anexado à lista de books como um dicionário, que pode ser facilmente armazenado em um arquivo JSON.
Agora que você concluiu o processo de web scraping, é hora de salvar esses dados localmente. Abra seu arquivo de script e insira o seguinte código:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
Nesse código, um novo arquivo chamado books.json é criado. Esse arquivo é preenchido usando o método json.dump, que usa a lista books como origem e um objeto file como destino.
Você pode testar esse script abrindo o terminal e executando o seguinte comando:
python static_scrape.py
Esse comando gera um novo arquivo em seu diretório com a seguinte saída:
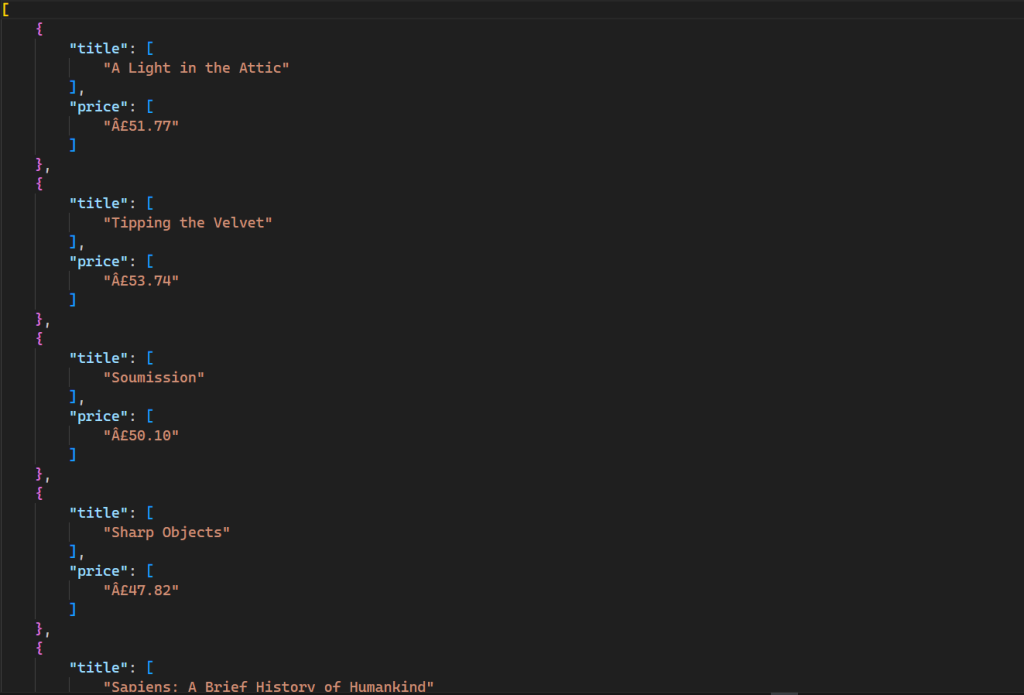
Todo o código para esse script está disponível no GitHub.
Analisando conteúdo HTML dinâmico
Extrair conteúdo dinâmico da web é mais complicado do que copiar conteúdo estático porque o JavaScript renderiza os dados continuamente, em vez de todos de uma vez. Para ajudar a coletar conteúdo dinâmico, você usa uma ferramenta de automação de navegador chamada Selenium, que permite criar e executar uma instância do navegador e controlá-la programaticamente.
Para instalar o Selenium, abra o terminal e execute o seguinte comando:
pip install selenium
YouTube é um ótimo exemplo de conteúdo renderizado usando JavaScript. Quando você visita qualquer canal, apenas um número limitado de vídeos é carregado inicialmente, com mais vídeos aparecendo conforme você rola para baixo. Aqui, você coleta dados dos cem melhores vídeos do canal freeCodeCamp.org no YouTube emulando pressionamentos no teclado para rolar a página.
Para começar, inspecione o código HTML da página da web. Ao abrir Dev Tools, você verá o seguinte:
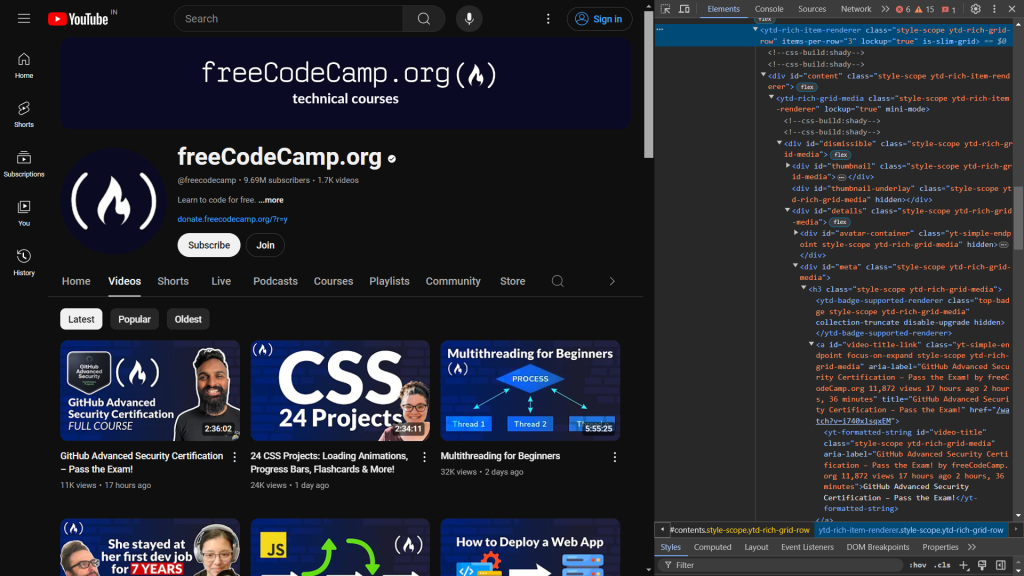
O código a seguir identifica os elementos responsáveis pela exibição do título e do link do vídeo:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>
O título do vídeo está dentro da tag yt-formatted-string com o ID video-title, e o link do vídeo está localizado no atributo href da tag a com o ID video-title-link.
Depois de identificar o que você deseja copiar, crie um novo arquivo chamado dynamic_scrape.py e adicione o seguinte código, que importa todos os módulos necessários para o script:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
Aqui, você começa importando webdriver do selenium, o que cria uma instância de navegador que você pode controlar programaticamente. As próximas linhas importam By e Keys, que selecionam um elemento na web e pressionam algumas teclas nele. A função sleep é importada para pausar a execução do programa e esperar que o JavaScript renderize o conteúdo na página.
Com todas as importações resolvidas, você pode definir a instância do driver para o navegador de sua escolha. Este tutorial usa Chrome, mas o Selenium também é compatível com Edge, Firefox e Safari.
Para definir a instância do driver para o navegador, acrescente o script com o seguinte código:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
Semelhante ao script anterior, você declara uma variável URL contendo o URL da web que você deseja copiar e uma variável videos que armazena todos os dados como uma lista. Em seguida, uma variável driver é declarada (ou seja, uma instância do Chrome ) que você usa quando interage com o navegador. A função get() abre a instância do navegador e envia uma solicitação para o URL especificado. Depois disso, você chama a função sleep para esperar três segundos antes de acessar qualquer elemento na página da web para garantir que todo o código HTML seja carregado no navegador.
Conforme mencionado anteriormente, o YouTube usa JavaScript para carregar mais vídeos à medida que você rola até o final da página. Para extrair dados de uma centena de vídeos, você deve rolar programaticamente até a parte inferior da página depois de abrir o navegador. Você pode fazer isso adicionando o seguinte código ao seu script:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
Nesse código, a tag <html> é selecionada usando a função find_element. Ela retorna o primeiro elemento que corresponde aos critérios fornecidos, que nesse caso é a tag html. O método send_keys simula pressionar a tecla END para rolar até o final da página, acionando o carregamento de mais vídeos. Essa ação é repetida quatro vezes em um loop de for para garantir que vídeos suficientes sejam carregados. A função sleep pausa por três segundos após cada rolagem para permitir que os vídeos sejam carregados antes de rolar novamente.
Agora que você tem todos os dados necessários para iniciar o processo de coleta, é hora de usar lxml com cssselect para selecionar os elementos que deseja extrair:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
Nesse código, você passa o conteúdo HTML do atributo page_source do driver para o método fromstring, que cria uma árvore hierárquica do HTML. Em seguida, você seleciona todas as tags <a> com o ID video-title-link usando seletores CSS, onde o sinal # indica a seleção usando o ID da tag. Essa seleção retorna uma lista de elementos que atendem aos critérios fornecidos. O código então itera sobre cada elemento para extrair o título e o link. O método text_content recupera o texto interno (o título do vídeo), enquanto o método get busca o valor do atributo href (o link do vídeo). Finalmente, os dados são armazenados em uma lista chamada videos.
Neste ponto, você concluiu o processo de extração de dados. A próxima etapa envolve armazenar tais dados coletados localmente em seu sistema. Para armazenar os dados, acrescente o seguinte código no script:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
Aqui, você cria um arquivo videos.json e usa o método json.dump para serializar a lista de vídeos no formato JSON e gravá-la no objeto de arquivo. Finalmente, você chama o método close no objeto do driver para fechar e destruir com segurança a instância do navegador.
Agora, você pode testar seu script abrindo o terminal e executando o seguinte comando:
python dynamic_scrape.py
Depois de executar o script, um novo arquivo chamado videos.json é criado em seu diretório:
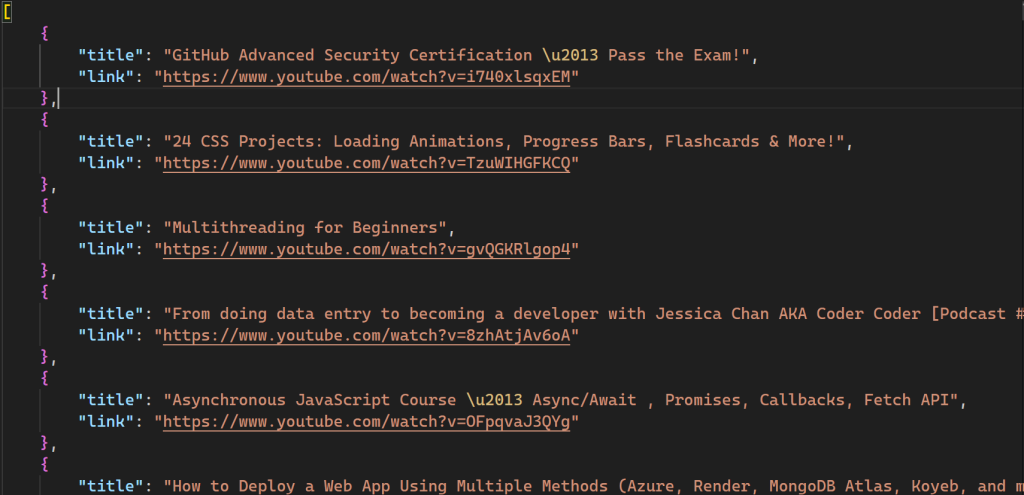
Todo o código para esse script também está disponível no GitHub.
Usando lxml com o proxy da Bright Data
Embora a extração de dados da web seja uma ótima técnica para automatizar a coleta de dados de várias fontes, o processo tem seus desafios. Você precisa lidar com ferramentas anti-scraping implementadas por sites, limitação de taxas, bloqueio geográfico e falta de anonimato. Servidores proxy podem ajudar com esses problemas agindo como intermediários que mascaram o endereço IP do usuário, permitindo que os raspadores contornem as restrições e acessem os dados direcionados sem serem detectados. Bright Data é a melhor escolha para serviços de proxy confiáveis.
O exemplo a seguir destaca como é fácil trabalhar com proxies da Bright Data. O processo envolve fazer algumas alterações no arquivo script_scrape.py para copiar o site Books to Scrape.
Para começar, você precisa obter proxies da Bright Data inscrevendo-se para um teste gratuito, que fornece recursos de proxy no valor de US$ 5. Depois de criar uma conta Bright Data, você verá o seguinte painel:
Navegue até a opção Minhas zonas e crie uma nova zona proxy residencial . A criação de uma nova zona revela seu nome de usuário, senha e host do proxy, necessários na próxima etapa.
Abra o arquivo static_scrape.py e adicione o seguinte código abaixo da variável URL:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
Substitua os espaços reservados username, passworde hostname pelas suas credenciais de proxy. Esse código instrui a biblioteca requests a usar o proxy especificado. O resto do seu script permanece inalterado.
Teste seu script executando o seguinte comando:
python static_scrape.py
Depois de executar esse script, você verá um resultado semelhante ao que recebeu no exemplo anterior.
Você pode ver esse script inteiro em GitHub.
Conclusão
lxml é uma ferramenta robusta e fácil de usar para extrair dados de documentos HTML. O lxml é otimizado para velocidade e suporta seletores XPath e CSS, permitindo a análise eficiente de grandes documentos XML e HTML.
Neste tutorial, você aprendeu tudo sobre extração de dados da web com lxml e coleta de conteúdo dinâmico e estático. Você também aprendeu como o uso de servidores proxy da Bright Data pode ajudá-lo a contornar as restrições impostas por sites contra raspadores.
A Bright Data é uma solução completa para todos os seus projetos de web scraping. Ela oferece recursos como proxies, navegadores para extração de dados e reCAPTCHAs que permitem que os usuários resolvam com eficácia os desafios de web scraping. A Bright Data também oferece um blog detalhado com tutoriais e melhores práticas relacionadas a web scraping.
Interessado em começar? Inscreva-se agora e teste nossos produtos gratuitamente!






