

Neste artigo, você aprenderá como coletar manualmente dados financeiros e como usar a API da Bright Data para raspagem de dados financeiros e automatizar o processo.
Saiba o que você quer coletar e como está organizado
Os dados financeiros abrangem uma ampla e muitas vezes complexa gama de informações. Antes de começar a raspagem de dados, você precisa identificar claramente o tipo de dados que você precisa.
Por exemplo, você pode querer raspar preços de ações que mostram o preço mais recente de uma ação, bem como seu preço de abertura e fechamento do dia, os valores máximos e mínimos alcançados durante o dia e quaisquer alterações de preço ocorridas ao longo do tempo. Detalhes financeiros como as demonstrações de resultados de uma empresa, balanços patrimoniais (que detalham ativos e passivos) e demonstrações de fluxo de caixa (que acompanham o dinheiro que entra e sai) também são necessários para avaliar o desempenho. Índices financeiros, avaliações de analistas e relatórios podem orientar decisões de compra e venda, enquanto atualizações recentes e análise de sentimentos nas redes sociais oferecem mais visões sobre as tendências do mercado.
Entender como os dados em uma página da Web são organizados pode facilitar a localização e a coleta do que você precisa.
Analise considerações legais e éticas
Antes de criar um site, certifique-se de revisar os termos de serviço desse site. Muitos sites proíbem a raspagem de dados sem consentimento ou autorização prévia.
Você também precisa seguir as regras do arquivo robots.txt , que mostra quais partes do site você pode acessar. Além disso, certifique-se de não sobrecarregar o servidor com solicitações e implementar atrasos entre suas solicitações. Isso ajuda a proteger os recursos do site e evita problemas.
Use as ferramentas de desenvolvimento do navegador
Para visualizar os elementos HTML de uma página da Web, você pode usar as ferramentas de desenvolvedor do seu navegador. Essas ferramentas são incorporadas à maioria dos navegadores modernos, incluindo Chrome, Safari e Edge. Para abrir as ferramentas do desenvolvedor, pressione Ctrl + Shift + I no Windows, Cmd + Option + I no Mac ou clique com o botão direito na página e selecione Inspecionar.
Depois de aberta, você pode inspecionar a estrutura HTML da página e identificar elementos de dados específicos. A guia Elements exibe a árvore Document Object Model (DOM), permitindo localizar e destacar elementos na página. A guia Rede mostra todas as solicitações de rede, o que é útil para encontrar endpoints de API ou dados carregados dinamicamente. A guia Console permite que você execute comandos JavaScript e interaja com os scripts da página.
Neste tutorial, você vai fazer raspagem de dados das ações da APPL do Yahoo Finance. Para encontrar as tags HTML relevantes, navegue até a página ações da APPL , clique com o botão direito do mouse em um preço exibido na página e clique em Inspecionar. A guia Elements destaca o elemento HTML que contém o preço:

Anote o nome da tag e quaisquer atributos exclusivos, como class ou id, para ajudar a localizar esse elemento em seu raspador.
Como configurar o ambiente e o projeto
Este tutorial usa [Python]((https://www.python.or) para raspagem de dados devido à sua simplicidade e às bibliotecas disponíveis. Antes de começar, certifique-se de ter o Python 3.10 ou versão mais recente instalado no seu sistema.
Depois de instalar o Python, abra seu terminal ou shell e execute os seguintes comandos para criar um diretório e um ambiente virtual:
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
Depois que seu ambiente virtual for criado, você ainda precisará ativá-lo. Os comandos de ativação variam de acordo com seu sistema operacional.
Se você estiver usando o Windows, execute o seguinte comando:
.myenvScriptsactivate
Se você estiver no macOS/Linux, execute este comando:
source myenv/bin/activate
Depois de ativar o ambiente virtual, instale as bibliotecas necessárias com pip:
pip3 install requests beautifulsoup4 lxml
Esse comando instala a biblioteca Requests para lidar com solicitações HTTP, Beautiful Soup para analisar conteúdo HTML e lxml para uma análise eficiente de XML e HTML.
Como raspar dados financeiros manualmente
Para coletar dados financeiros manualmente, crie um arquivo chamado manual_scraping.py e adicione o seguinte código para importar as bibliotecas necessárias:
import requests
from bs4 import BeautifulSoup
Defina o URL dos dados financeiros que você deseja coletar. Conforme mencionado anteriormente, este tutorial usa a página do Yahoo Finance para as ações da Apple (AAPL):
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
Depois de definir o URL, envie uma solicitação GET para o URL:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Esse código inclui um cabeçalho User-Agent para imitar uma solicitação do navegador, o que ajuda a evitar ser bloqueado pelo site de destino.
Verifique se a solicitação foi bem-sucedida:
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
Em seguida, analise o conteúdo da página da Web usando o analisador lxml :
soup = BeautifulSoup(response.content, 'lxml')
Encontre os elementos com base em seus atributos exclusivos, extraia o conteúdo do texto e imprima os dados extraídos:
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
Execute e teste o código
Para testar o código, abra o terminal ou shell e execute o seguinte comando:
python3 manual_scraping.py
O resultado deve ser semelhante a este:
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
Enfrente desafios com a raspagem manual
A coleta manual de dados pode ser um desafio por vários motivos, incluindo a necessidade de lidar com CAPTCHAs ou bloqueios de IP, que exigem estratégias para contornar obstáculos. Dados não estruturados ou confusos podem causar erros de análise, enquanto a coleta sem as devidas permissões pode levar a problemas legais. Atualizações frequentes de sites também podem quebrar o seu raspador de dados, exigindo manutenção regular do código para garantir o funcionamento contínuo.
Para criar e automatizar seu raspador de dados, você precisa gastar muito tempo escrevendo o código e corrigindo-o, em vez de se concentrar na análise dos dados. Se você está lidando com grandes quantidades de dados, pode ser ainda mais difícil, pois você precisa garantir que os dados estejam limpos e organizados. Se você está gerenciando diferentes estruturas de sites, você também precisa entender várias tecnologias da Web.
Ou seja, se você precisar raspar dados com frequência e rapidez, a raspagem de dados manual na Web não é sua melhor opção.
Como coletar dados com a API da Bright Data para raspagem de dados financeiros
A Bright Data aborda os desafios da coleta manual com sua API para raspagem de dados financeiros, que automatiza a extração de dados. Ela vem com gerenciamento de proxy integrado com proxies rotativos para evitar bloqueios de IP. A API retorna dados estruturados em formatos como JSON e CSV. Também é altamente escalável, facilitando o manuseio de grandes volumes de dados.
Para usar a API para raspagem de dados financeiros, inscreva-se em uma conta gratuita no site Bright Data. Verifique seu endereço de e-mail e conclua todas as etapas de verificação de identidade necessárias.
Depois que sua conta estiver configurada, faça login para acessar o painel e obter suas chaves de API.
Configure a API para raspagem de dados financeiros
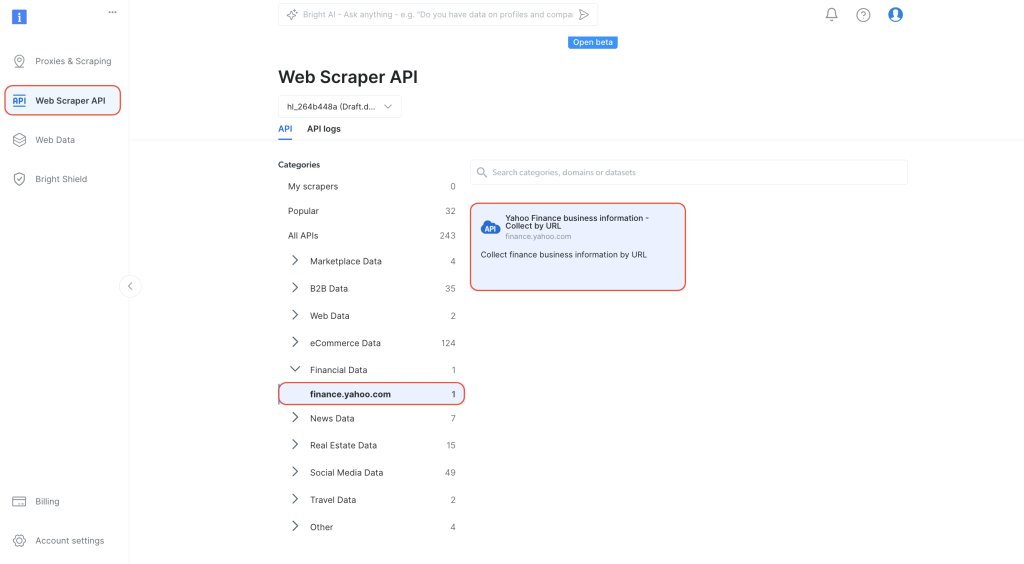
No painel, navegue até Web Scraper API na guia de navegação à esquerda. Selecione
Dados financeiros em Categorias e clique para abrir as Informações comerciais do Yahoo Finance — Coletar por URL:
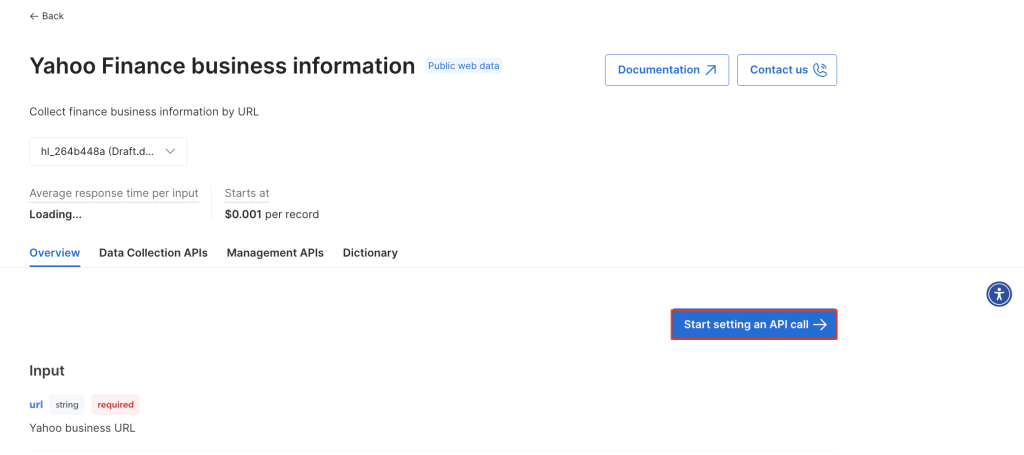
Clique em Começar a definir uma chamada de API:
Para usar a API, você precisa criar um token que autentique suas chamadas de API no raspador de dados da Bright Data. Para criar um novo token, clique em Criar token:

Uma caixa de diálogo será aberta. Defina as Permissões como “Admin” e escolha a duração “Ilimitada”:

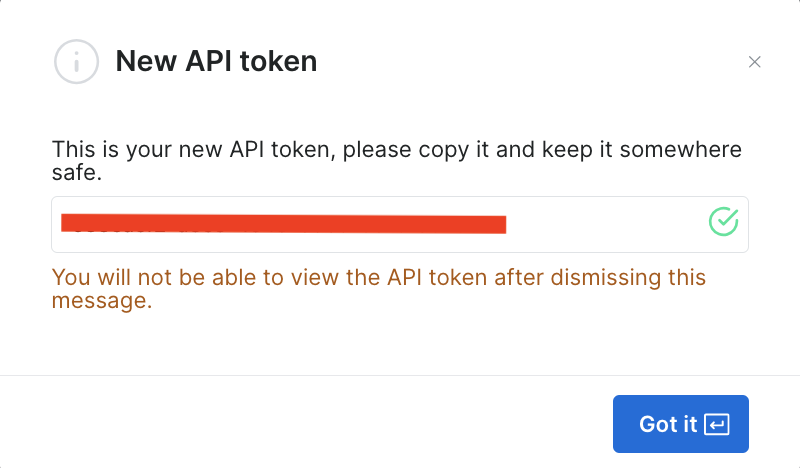
Depois de salvar essas informações, o token é criado e você receberá um aviso sobre o novo token. Certifique-se de salvá-lo em algum lugar seguro, pois você precisará dele novamente em breve:
Se você já criou o token, você pode obtê-lo nas configurações do usuário, em Tokens de API. Selecione a guia Mais do seu usuário e clique em Copiar token.
Execute o raspador de dados para recuperar dados financeiros
Na página Informações comerciais do Yahoo Finance , adicione seu token de API no campo token de API e, em seguida, adicione o URL de ações do site de destino, que é https://finance.yahoo.com/quote/AAPL/. Copie a solicitação na seção SOLICITAÇÃO AUTENTICADA à direita:
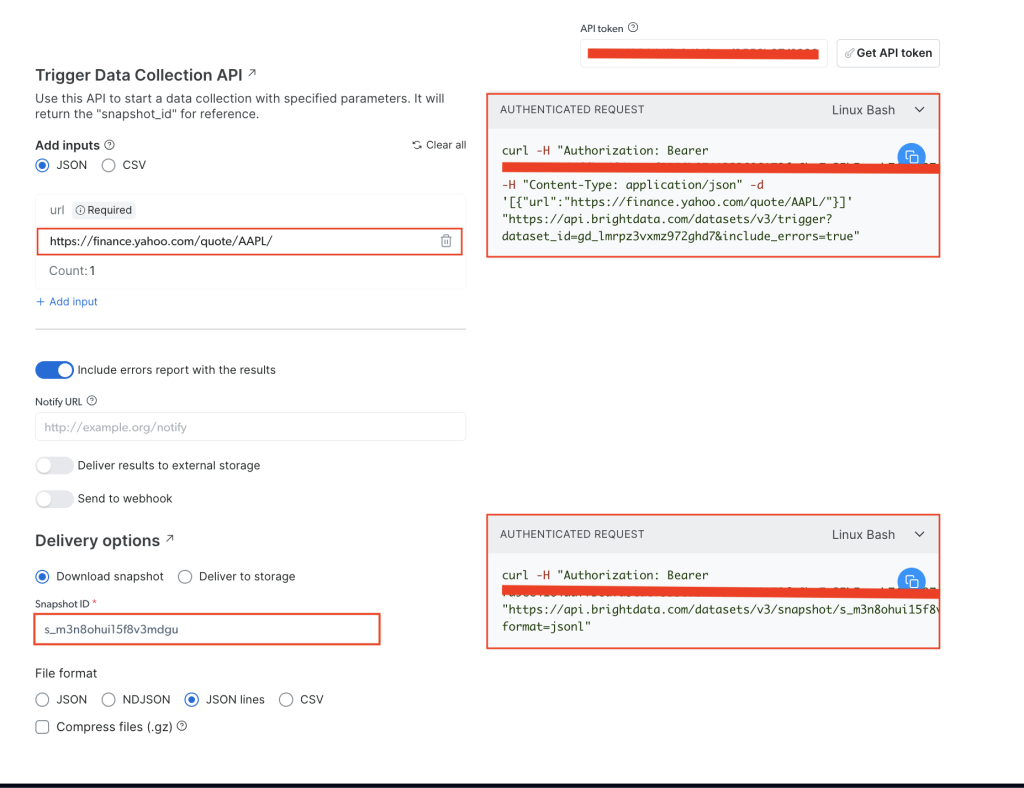
Abra seu terminal ou shell e execute a chamada de API usando curl. Deve ter a seguinte aparência:
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
Depois de executar o comando, você obterá snapshot_id como resposta:
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
Copie o snapshot_id e execute a seguinte chamada de API do seu terminal ou shell:
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
Certifique-se de substituir
YOUR_TOKENeYOUR_SNAP_SHOT_IDpor suas credenciais.
Depois de executar esse código, você deve obter os dados copiados como saída. Os dados devem ser semelhantes ao seguinte arquivo JSON.
Caso você receba uma resposta informando que o snapshot não está pronto, aguarde dez segundos e tente novamente.
A API da Bright Data para raspagem de dados financeiros extraiu todos os dados necessários sem exigir que você analise a estrutura HTML ou localize tags específicas. Ela recuperou os dados da página inteira, incluindo campos adicionais como earning_estimate, earnings_historye growth_estimates.
Todo o código deste tutorial está disponível neste repositório do GitHub.
Benefícios de usar a API da Bright Data
A API da Bright Data para raspagem de dados financeiros simplifica o processo de raspagem de dados ao eliminar a necessidade de escrever ou gerenciar código de raspagem. A API também ajuda a garantir a conformidade gerenciando a rotação de proxy e aderindo aos termos de serviço do site, permitindo que você colete dados sem medo de ser bloqueado ou violar as regras.
A API da Bright Data para raspagem de dados financeiros fornece dados estruturados e confiáveis com poucos códigos. Ela gerencia a navegação da página e a análise de HTML para você, simplificando o processo. A escalabilidade da API permite que você colete dados sobre várias ações e outras métricas financeiras sem fazer grandes alterações em seu código. A manutenção também é mínima porque a Bright Data atualiza o raspador de dados quando os sites mudam sua estrutura, para que sua coleta de dados continue sem problemas, sem nenhum trabalho extra.
Conclusão
Coletar dados financeiros é uma tarefa crítica para desenvolvedores e equipes de dados envolvidas em análise financeira, negociação algorítmica e pesquisa de mercado. Neste artigo, você aprendeu como coletar dados financeiros manualmente usando Python e a API da Bright Data para raspagem de dados financeiros. Embora a coleta manual de dados forneça controle, pode ser difícil lidar com medidas antirraspagem e sobrecarga de manutenção, além de ser difícil de escalar.
A API da Bright Data para raspagem de dados financeiros simplifica a coleta de dados gerenciando tarefas complexas, como rotação de proxy e resolução de CAPTCHA. Além da API, a Bright Data também oferece conjuntos de dados, proxies residenciaise o navegador para raspagem de dados para aprimorar seus projetos de raspagem de dados na Web. Inscreva-se para um teste gratuito para explorar tudo o que a Bright Data tem a oferecer.





