

O rastreamento distribuído da Web é uma estratégia para dimensionar raspadores da Web em várias máquinas, superando assim as limitações dos rastreadores de nó único. Neste artigo, exploraremos:
- Rastreamento distribuído da Web versus rastreamento de nó único
- A arquitetura central do rastreamento distribuído da Web
- Exemplos reais de rastreamento distribuído da Web
- Estratégias de implementação e práticas recomendadas
- Armadilhas comuns e como corrigi-las
TL;DR: o rastreamento distribuído da Web usa um cluster de máquinas para rastrear sites em paralelo, resolvendo os desafios de escalabilidade e velocidade que os rastreadores de nó único não conseguem enfrentar. Ele oferece maior taxa de transferência e confiabilidade (sem gargalo único) ao custo de maior complexidade arquitetônica e sobrecarga.
Rastreamento distribuído versus rastreamento de nó único
A maioria dos projetos de rastreamento não precisa de sistemas distribuídos, mas as equipes costumam perder meses criando arquiteturas distribuídas complexas quando um único servidor seria suficiente.
Em um rastreador de nó único, uma máquina lida com toda a busca, análise e armazenamento. Esse tipo de sistema é mais fácil de desenvolver e manter, além de economizar dinheiro. É ótimo para buscar de 60 a 500 páginas por minuto, mas, à medida que suas necessidades de rastreamento aumentam, um único nó se torna um gargalo porque você estará limitado pelas restrições de CPU, memória e rede.
Em contrapartida, os rastreadores distribuídos distribuem o trabalho em vários nós, permitindo a busca simultânea em escala, alta velocidade e maior tolerância a falhas. Se um trabalhador falhar, os outros continuarão em execução, aumentando assim a confiabilidade. A desvantagem é que os sistemas distribuídos exigem filas de mensagens, sincronização de uma fronteira de URL e um projeto cuidadoso para evitar a duplicação ou a sobrecarga dos sites de destino.
Comparação abrangente
| Aspecto | Nó único | Distribuído |
|---|---|---|
| Desempenho | Média de 4 segundos/página, 60-120 páginas/minuto | 30 vezes mais rápido, mais de 50.000 solicitações/segundo |
| Escalabilidade | Limitado por recursos de uma única máquina | Dimensionamento linear entre nós |
| Tolerância a falhas | Ponto único de falha | Failover automático, autocorreção |
| Distribuição geográfica | Local fixo | Implementação em várias regiões |
| Utilização de recursos | Somente escalonamento vertical | Dimensionamento horizontal otimizado |
| Complexidade | Configuração simples, sobrecarga mínima | Orquestração complexa, custo operacional mais alto |
| Custo | Menor investimento inicial | Custos de infraestrutura mais altos, melhor ROI em escala |
| Manutenção | Carga operacional mínima | Requer experiência em sistemas distribuídos |
| Processamento de dados | Somente processamento local | Processamento paralelo entre nós |
| Anti-detecção | Rotação limitada de IP | Gerenciamento avançado de proxy, impressão digital |
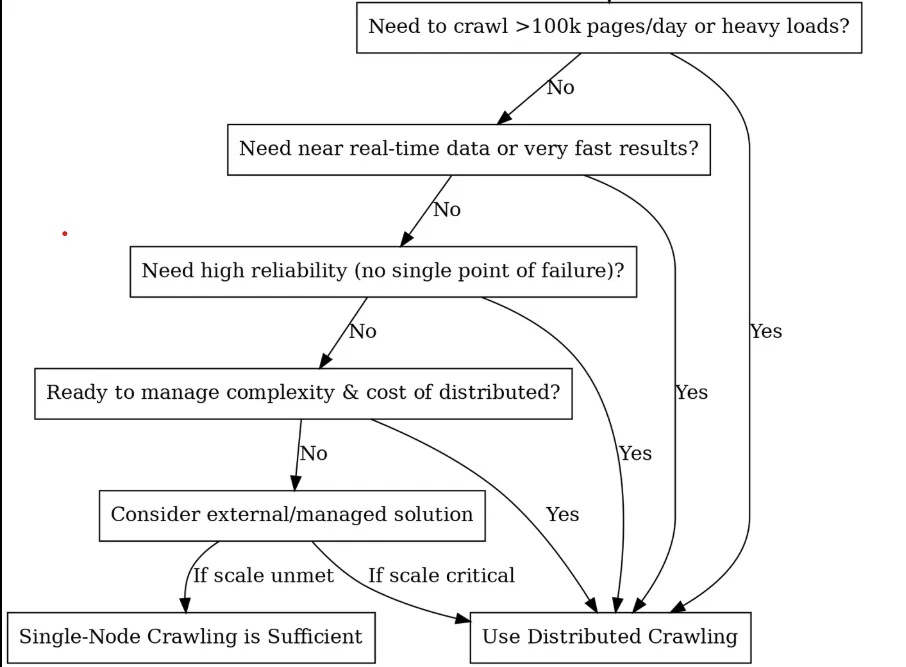
Você deve optar pela distribuição? (Uma árvore de decisão)
Blocos de construção principais e arquitetura
Depois de decidir usar o rastreamento distribuído, a próxima etapa é detalhar o que você está realmente construindo. Pense nisso como a montagem de uma equipe de corrida de alto desempenho, em que cada componente tem uma função específica e todos precisam trabalhar juntos sem problemas. Aqui estão os principais componentes necessários para criar um sistema de rastreamento distribuído:
Agendador / Fila (O cérebro)
No centro de um rastreador distribuído está um agendador ou uma fila de tarefas que coordena o trabalho entre os nós, e é onde seus URLs ficam antes de serem rastreados. Um componente de agendador também pode lidar com polidez (tempo) e novas tentativas. Por exemplo, você pode implementar filas específicas de domínio para garantir que um site não seja atingido por todos os trabalhadores ao mesmo tempo.
Com os agendadores, você tem três opções principais, cada uma com sua própria personalidade:
- Kafka: Esse é o campeão dos pesos pesados. Ele foi desenvolvido para um rendimento maciço e não se cansa de lidar com milhões de mensagens por segundo. A beleza está em seu design baseado em log, que é perfeito para gerenciar sua fronteira de URL. Você pode particionar por domínio para manter o rastreamento polido.
- RabbitMQ: é como um canivete suíço. Roteamento mais flexível do que o Kafka, com recursos como filas prioritárias. O RabbitMQ tem armazenamento na memória, por isso é mais rápido para cargas de trabalho menores. Excelente quando você precisa de diferentes estratégias de rastreamento para diferentes tipos de conteúdo.
- Aipo: O melhor amigo do desenvolvedor Python. Essa opção não é tão eficiente quanto as outras, mas é fácil de usar. O Celery é perfeito para prototipagem ou rastreamento em escala média quando você precisa fazer algo funcionar rapidamente.
Fronteira de URL e deduplicação: A memória do rastreador
Você já rastreou acidentalmente a mesma página 1.000 vezes? É aí que a deduplicação o salva. Você precisa rastrear o que viu e, ao mesmo tempo, respeitar a educação do servidor, para não martelar repetidamente o mesmo domínio.
Os Redis Sets podem lhe dar uma precisão perfeita, mas consomem muita memória. Os Bloom Filters usam 90% menos memória (1,2 GB vs. mais de 12 GB para um bilhão de URLs), mas ocasionalmente apresentam falsos positivos (eles podem dizer que você não viu um URL quando já viu), portanto, talvez seja melhor optar por essa implementação do Redis:
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# Skip if already seen
if self.redis.sismember("seen_urls", url):
return
# Mark as seen and queue by domain
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# Get highest priority URL
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# Respect crawl delay (1 second between requests per domain)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# Remove from queues and update last crawl time
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
Nós de trabalho (o músculo)
Os nós de trabalho são os cavalos de batalha do rastreamento. Eles são os processos ou máquinas que realmente realizam o trabalho de rastreamento, como buscar URLs e processar o conteúdo. Cada worker executa uma lógica de rastreamento idêntica (por exemplo, o mesmo script ou aplicativo Python), mas opera em paralelo em diferentes URLs da fila.
Para tirar o máximo proveito dos seus workers, você precisa mantê-los sem estado, de modo que qualquer estado (URLs visitados, resultados etc.) seja armazenado em um storage compartilhado ou transmitido por mensagens. Dessa forma, qualquer trabalhador pode assumir qualquer tarefa e, quando um morre, os outros assumem o controle instantaneamente, sem perder o ritmo.
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
Dica profissional: com os workers, é importante não usar uma marreta para tudo. Você deve usar workers HTTP leves para HTML estático e workers pesados do Puppeteer para páginas renderizadas em JavaScript. Ferramentas diferentes, pools de workers diferentes. Você pode escolher facilmente os tipos de proxy certos para sua frota de workers com nosso abrangente guia de seleção de proxy.
Camada de armazenamento (o armazém)
A camada de armazenamento é onde você salva os dados e metadados rastreados, e geralmente consiste em duas partes:
- O Content Storage lida com o grande volume de HTML bruto, respostas JSON, imagens e PDFs. Pense nele como seu depósito digital. Os armazenamentos de objetos, como o S3, o Google Cloud Storage ou o HDFS, são excelentes nesse caso, pois são escalonados infinitamente e lidam com gravações simultâneas de vários funcionários sem esforço.
- O armazenamento de metadados mantém o ouro estruturado que você extraiu – campos analisados, relacionamentos de entidades, registros de data e hora de rastreamento e status de sucesso/falha. Isso vai para bancos de dados otimizados para consultas e atualizações, não apenas para o volume de armazenamento.
Os rastreadores distribuídos precisam de um armazenamento que lide com gravações simultâneas em massa sem engasgar. Os armazenamentos de objetos, como o S3 ou o Google Cloud Storage, são excelentes para conteúdo bruto porque são escalonados infinitamente, enquanto os bancos de dados NoSQL (MongoDB, Cassandra) ou SQL lidam com metadados estruturados de forma eficaz.
Monitoramento e alertas
A operação de um rastreador distribuído exige visibilidade do desempenho do sistema. Você pode usar o Prometheus e o Grafana para criar painéis de monitoramento abrangentes que monitoram as taxas de rastreamento, as taxas de sucesso, os tempos de resposta e a profundidade das filas. As principais métricas incluem solicitações por segundo por domínio, tempos de resposta do percentil 95 e tendências de tamanho de fila.
Camada antibot e de evasão
O rastreamento da Web em escala significa jogos constantes de gato e rato com sistemas antibot. Você precisa de três camadas de defesa: rotação de IP em milhares de proxies residenciais e de data center, randomização de impressão digital de agentes de usuário e assinaturas de navegador e imitação de comportamento para evitar padrões de detecção.
O Bright Data Web Unlocker oferece recursos antidetecção de nível empresarial com uma taxa de sucesso de mais de 99%, obtida por meio da solução automática de CAPTCHA, rotação de IP e impressão digital do navegador. Sua abordagem baseada em API simplifica a integração e, ao mesmo tempo, lida com desafios complexos de antibot.
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
A rotação avançada de proxy implementa verificação de integridade, otimização geográfica e recuperação de falhas em pools de proxy residenciais, de data center e móveis. O gerenciamento bem-sucedido de proxy requer mais de 1.000 IPs com algoritmos de rotação inteligentes.
A prevenção de impressões digitais randomiza agentes de usuários, impressões digitais de navegadores e características de rede para evitar a detecção por sistemas antibot sofisticados. Isso inclui rotação de impressão digital TLS, falsificação de impressão digital de tela e simulação de padrão comportamental.
Casos de uso no mundo real com exemplos de código
Vamos explorar dois casos de uso comuns para rastreadores distribuídos e descrever como é possível implementá-los com trechos de código. Usaremos Python e Celery nos exemplos para simplificar, mas os princípios se aplicam de forma geral.
Caso de uso 1: monitoramento de preços de comércio eletrônico
Imagine que você esteja rastreando os preços dos concorrentes em 50.000 páginas de produtos todos os dias. Se você tentar usar uma única máquina para acessar todos esses URLs, terá mais de 12 horas de rastreamento, supondo que nada seja interrompido. Além disso, a maioria dos sites de comércio eletrônico começará a bloqueá-lo após alguns milhares de solicitações rápidas do mesmo IP.
É aqui que o rastreamento distribuído ajuda. Em vez de uma máquina sobrecarregada, você distribui esses 50.000 URLs entre dezenas de trabalhadores, cada um usando endereços IP diferentes. O que costumava levar meio dia agora é concluído em 2 a 3 horas, e você passa despercebido pelos sistemas antibot.
A configuração é simples. Você precisa manter as listas de URLs de seus concorrentes (obtê-las de sitemaps ou rastreamentos de descoberta) e, em seguida, usar algo como Celery com Redis para distribuir o trabalho. Todas as manhãs, você coloca todos os 50.000 URLs na fila e seu exército de trabalhadores começa a trabalhar. O Trabalhador 1 lida com os tênis de corrida da Nike, o Trabalhador 2 lida com os tênis da Adidas, o Trabalhador 3 pega os preços da Puma. Tudo simultaneamente, tudo de IPs diferentes.
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Initialize Celery app with Redis as broker
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# Realistic user agents for rotation
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# Proxy pool (replace with your actual proxy service)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# Add your proxy endpoints here
]
def get_session_with_retries():
"""Create a session with retry strategy and random proxy."""
session = requests.Session()
# Retry strategy for resilience
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# Random proxy rotation
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""Fetches product price with full anti-detection measures."""
# Human-like delay before starting
time.sleep(random.uniform(2, 8))
# Randomized headers to avoid fingerprinting
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# Parse the page for price
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# Store in database (implement your storage logic here)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "Price not found", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"Request failed for {url}: {e}")
# Retry with exponential backoff
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""Extract price using multiple strategies."""
# Site-specific selectors (customize for each competitor)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# Try configured selectors first
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# Try data attributes as fallback
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# Clean and parse price
return parse_price(price_text)
def parse_price(price_text):
"""Parse price from various formats."""
# Remove common currency symbols and whitespace
cleaned = re.sub(r'[^\d.,]', '', price_text)
# Handle formats like "1,299.99" or "1299.99"
try:
# Remove commas and convert to float
if ',' in cleaned and '.' in cleaned:
# Format: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# Could be European format: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# Format: 1,299 (no cents)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"Could not parse price from: {price_text}")
return None
def store_price_data(url, price, status_code):
"""Store price data in your database."""
# Implement your storage logic here
# Could be PostgreSQL, MongoDB, or any other database
print(f"Storing: {url} -> ${price} (Status: {status_code})")
# Site-specific configurations for better accuracy
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""Get site-specific configuration."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# Load your 50k product URLs (from database, file, or API)
def load_product_urls():
"""Load URLs from your data source."""
# Replace with your actual data loading logic
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998 more URLs
]
return urls
# Main execution: dispatch all crawling tasks
def start_daily_price_monitoring():
"""Start the daily price monitoring job."""
product_urls = load_product_urls()
print(f"Starting crawl for {len(product_urls)} URLs...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("All tasks queued successfully!")
# Run with: python -m celery worker -A price_monitor --loglevel=info
# Start monitoring with: start_daily_price_monitoring()
No código aprimorado acima, fetch_product_price é uma tarefa robusta do Celery projetada para monitoramento de preços em escala empresarial. Ao chamar delay(url, site_config) para cada URL, colocamos as tarefas em fila no Redis, onde mais de 100 funcionários podem pegá-las instantaneamente. A abordagem distribuída transforma um rastreamento de 12 horas em uma única máquina em uma operação de 2 a 3 horas em toda a sua frota de trabalhadores.
Principais considerações sobre a produção:
- O gerenciamento de proxy é essencial: este exemplo inclui um PROXY_POOL que alterna IPs por solicitação, essencial ao atingir 50.000 URLs. Sem isso, você estará basicamente fazendo DoS em sites-alvo a partir de um IP, garantindo bloqueios.
- Limitação de taxa por domínio: Mesmo com a distribuição, 50.000 URLs de um site concorrente acionarão alarmes se todos forem atingidos em minutos. Incluímos atrasos semelhantes aos humanos
(time.sleep(random.uniform(2, 8))), mas consideramos a limitação específica do domínio. - Agendamento e monitoramento. Use o Celery Beat para agendamento diário ou integre-o ao Airflow para fluxos de trabalho complexos. A função
start_daily_price_monitoring()pode ser acionada por meio do cron ou de sua plataforma de orquestração. - Integração do pipeline de dados. Após cada rastreamento, a função
store_price_data()salva os resultados em seu banco de dados. - Resiliência a falhas. O código inclui lógica de repetição com backoff exponencial, mas planeje falhas parciais. Se 5% dos URLs falharem consistentemente, investigue se esses produtos foram descontinuados, movidos ou se esses sites específicos têm medidas antibot mais fortes que exigem abordagens diferentes.
Caso de uso 2: SEO e pesquisa de mercado
O SEO e a pesquisa de mercado exigem o rastreamento de milhões de páginas em dois fluxos críticos: análise de conteúdo e monitoramento de mecanismos de pesquisa. Não se trata apenas de raspagem, mas de criação de inteligência competitiva que exige velocidade, discrição e precisão.
Se você quiser rastrear menções de palavras-chave em 1 milhão de páginas de concorrentes e, ao mesmo tempo, monitorar as classificações SERP de centenas de palavras-chave alvo diariamente, uma única máquina levaria semanas e seria bloqueada em poucas horas. Isso exige uma arquitetura distribuída.
A abordagem de rastreamento distribuído da Web para isso pode ser dividida em dois fluxos:
- Inteligência de conteúdo: Rastreie sites de concorrentes, agências de notícias e blogs do setor para rastrear a densidade de palavras-chave, lacunas de conteúdo e tendências de mercado
- Vigilância SERP: Monitore as classificações do Google/Bing para suas palavras-chave alvo, acompanhando as posições dos concorrentes e as alterações nos recursos de SERP
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Initialize Celery and Redis
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# Anti-detection configurations
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# Add your proxy endpoints
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # Surrounding text snippets
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# Deduplication utilities
def get_url_hash(url: str) -> str:
"""Generate consistent hash for URL deduplication."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""Check if URL was already processed today."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""Mark URL as processed with 24h expiry."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# Stream 1: Content Intelligence Crawling
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""Crawl a page and extract keyword intelligence."""
# Skip if already processed today
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# Human-like delay
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# Extract content and analyze keywords
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# Store results
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"Content crawl failed for {url}: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""Extract keyword data from page content."""
# Remove script and style elements
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# Get clean text content
text = soup.get_text()
text = re.sub(r'\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# Find all occurrences
pattern = r'\b' + re.escape(keyword_lower) + r'\b'
matches = list(re.finditer(pattern, text))
if matches:
# Extract context around each match
contexts = []
for match in matches[:5]: # Limit to first 5 for performance
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# Stream 2: SERP Tracking
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""Track SERP positions for a keyword."""
time.sleep(random.uniform(5, 10)) # Longer delay for search engines
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# Special headers for search engines
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# Parse SERP results
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# Store SERP data
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP tracking failed for '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""Parse search engine results page."""
results = []
position = 1
if search_engine == "google":
# Google result selectors
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # Limit to top 20
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# Data storage functions
def store_keyword_data(keyword_data: List[KeywordData]):
"""Store keyword intelligence in database."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# Store in your preferred database (PostgreSQL, MongoDB, etc.)
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"Stored: {kd.keyword} found {kd.frequency} times on {kd.domain}")
def store_serp_data(serp_data: List[SERPResult]):
"""Store SERP tracking data."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# Orchestration functions
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""Launch content crawling across 1M+ URLs."""
print(f"Starting content intelligence crawl for {len(urls)} URLs...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"Queued {len(urls)} content crawling tasks")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""Launch SERP tracking for target keywords."""
print(f"Starting SERP tracking for {len(keywords)} keywords...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"Queued {len(keywords) * len(search_engines)} SERP tracking tasks")
# Example usage
if __name__ == "__main__":
# Target keywords for analysis
target_keywords = [
"artificial intelligence", "machine learning", "data science",
"cloud computing", "cybersecurity", "digital transformation"
]
# URLs to crawl for content intelligence (load from your database)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997 more URLs
]
# Keywords to track in SERPs
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# Launch both crawling streams
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
Principais considerações sobre a produção:
- Desduplicação inteligente: O sistema usa o Redis com expiração de 24 horas para evitar o rastreamento diário do mesmo conteúdo. Para uma desduplicação mais profunda, considere o hashing de conteúdo para detectar páginas que mudaram de URL, mas mantiveram o mesmo conteúdo.
- Limitação de taxa com reconhecimento de domínio: O rastreamento de SERP precisa de cuidado extra, pois os mecanismos de pesquisa são mais agressivos quanto ao bloqueio. Nosso exemplo inclui atrasos maiores (5 a 10 segundos) para consultas de pesquisa em comparação com o rastreamento de conteúdo (3 a 7 segundos).
- Rastreamento de recursos SERP: O analisador lida com os resultados do Google e do Bing, mas você pode estendê-lo para rastrear snippets em destaque, pacotes locais e outros recursos de SERP que afetam sua estratégia de visibilidade.
- Integração de pipeline de dados: Armazene os resultados em seu banco de dados preferido (PostgreSQL para análise relacional, MongoDB para esquemas flexíveis).
Práticas recomendadas
Respeite o robots.txt ou enfrente as consequências
Analise o robots.txt antes de enfileirar URLs e respeite religiosamente as diretivas de atraso de rastreamento. Ignorar isso faz com que todo o seu intervalo de IP seja colocado na lista negra mais rápido do que você pode dizer “rastreador distribuído”. Crie a verificação do robots.txt diretamente em sua fronteira de URL e não a torne responsabilidade do nó de trabalho.
Além da conformidade com o robots.txt, você também deve implementar estratégias abrangentes de prevenção de detecção em toda a sua frota distribuída.
Sempre registre para depuração às 3 horas da manhã
Quando seu rastreamento morre à meia-noite, você precisa de metadados: URL, status HTTP, latência, ID do proxy, ID do trabalhador e registro de data e hora de cada solicitação. Os registros estruturados em JSON salvam sua sanidade. A questão não é se você precisará depurar uma falha na produção, mas sim quando.
Validar tudo, não confiar em nada
A validação de esquema nos dados extraídos é necessária para a sobrevivência de seus rastreadores distribuídos na Web, pois apenas uma resposta malformada pode envenenar todo o seu conjunto de dados. Verifique os tipos de campos, os campos obrigatórios e o frescor dos dados na ingestão. Detecte o lixo logo no início ou descubra que ele está corrompendo sua análise meses depois.
Combater impiedosamente a dívida de velocidade
Os sistemas distribuídos apodrecem rapidamente. Você precisa programar a limpeza mensal de chaves Redis obsoletas, filas de tarefas com falhas e processos de trabalho órfãos. Os URLs mortos se acumulam, os pools de proxy são poluídos com IPs bloqueados e os vazamentos de memória do worker aumentam com o tempo. A manutenção não é glamourosa, mas mantém seu rastreador saudável. A dívida técnica dos rastreadores aumenta exponencialmente, portanto, resolva-a antes que ela destrua seu sistema.
Armadilhas comuns do rastreamento distribuído e como evitá-las
Há várias armadilhas comuns que as pessoas enfrentam ao usar o rastreamento distribuído da Web, razão pela qual a maioria dos engenheiros busca alternativas, como os conjuntos de dados da Bright Data. Algumas dessas armadilhas incluem:
A armadilha do “ponto único de falha”
Construir tudo em torno de uma instância Redis ou coordenador mestre é uma má ideia. Quando ele morre, todo o seu rastreamento é interrompido.
Correção: use o Redis Cluster ou várias instâncias de broker. Projete para que o coordenador desapareça, de modo que os trabalhadores devem lidar com as interrupções do broker e se reconectar automaticamente.
A espiral da morte da repetição
Quando os URLs com falha voltam imediatamente para a fila principal, isso cria um loop infinito que prejudica os pontos de extremidade quebrados e obstrui seu pipeline.
Correção: Filas de novas tentativas separadas com backoff exponencial. Primeira tentativa após 1 minuto, depois 5, depois 30. Após 3 falhas, envie para uma fila de cartas mortas para revisão manual.
A falácia de que todos os trabalhadores são iguais
A distribuição de tarefas round-robin pressupõe que todos os trabalhadores tenham a mesma velocidade de rede, qualidade de proxy e capacidade de processamento. A realidade costuma ser mais confusa.
Correção: implemente a pontuação do trabalhador com base na taxa de sucesso, na latência e na taxa de transferência. Encaminhe os trabalhos mais difíceis para os de melhor desempenho.
A bomba-relógio de vazamento de memória
Os workers que nunca reiniciam acumulam vazamentos de memória, especialmente ao analisar HTML malformado ou lidar com respostas grandes. Se não forem reiniciados, o desempenho do rastreamento distribuído da Web se deteriora até que os workers falhem.
Correção: Reinicie os trabalhadores após o processamento de 1.000 tarefas ou a cada 4 horas. Monitore o uso da memória e implemente disjuntores.
Conclusão
Agora você tem o plano para o rastreamento distribuído que pode ser dimensionado para milhões de páginas. Para aprofundar seu conhecimento sobre os fundamentos do rastreamento da Web que sustentam os sistemas distribuídos, leia nossa visão geral abrangente do rastreador da Web.
A arquitetura é simples, mas a verdade brutal é que 90% das equipes ainda fracassam porque subestimam a complexidade antidetecção de um sistema distribuído de rastreamento da Web. O gerenciamento de milhares de proxies, a rotação de impressões digitais e o manuseio de CAPTCHAs tornam-se um pesadelo de engenharia em tempo integral que distrai a extração de dados valiosos.
É exatamente por isso que existe a API do Web Unlocker da Bright Data. Em vez de gastar meses criando uma infraestrutura proxy que quebra toda semana, seus funcionários distribuídos simplesmente encaminham as solicitações por meio da API com taxa de sucesso de mais de 99% do Web Unlocker.
Sem gerenciamento de proxy, sem rotação de impressões digitais, sem solução de CAPTCHA – apenas extração confiável de dados em escala. Sua equipe de engenharia se concentra na criação da lógica comercial, enquanto a Bright Data cuida dos jogos de gato e rato com sistemas anti-bot.
A matemática é simples: a antidetecção caseira custa meses de tempo de engenharia, além de dores de cabeça com a manutenção contínua, enquanto o Web Unlocker custa uma fração desse valor e oferece confiabilidade de nível empresarial. Portanto, pare de reinventar a roda e comece a extrair insights. Obtenha sua conta gratuita da Bright Data hoje mesmo e transforme seu rastreador distribuído de um fardo de manutenção em uma vantagem competitiva.





