

No gerenciamento diário de dados on-line e na coleta de dados na web, é comum encontrar mensagens de erro de proxy. Esses códigos de erro são indicadores cruciais de problemas de entrega de dados com proxies e desempenham um papel vital no diagnóstico e resolução dos problemas.
Este artigo descreve os diferentes tipos de códigos de erro de proxy HTTP, abrangendo os vários tipos, interpretações e condições nas quais geralmente surgem.
Códigos de erro de proxy
Erros de proxy podem ocorrer por vários motivos, incluindo tempo de inatividade do servidor ou configurações inconsistentes. Entender esses detalhes ajuda você a entender o que está errado, facilitando a correção.
Nas seções a seguir, você aprenderá sobre vários códigos de proxy e como solucioná-los e resolvê-los de forma eficaz.
Códigos 3xx: redirecionamentos
Um código de status HTTP 3xx é usado para redirecionamentos, indicando que o user-agent (agente do usuário) precisa realizar etapas adicionais para concluir a solicitação. Normalmente, esse código indica que você está sendo direcionado para um novo URL devido a mudanças editoriais ou reestruturação do site.
Quando se trata de extração de dados da web, você deve lidar com esses redirecionamentos para manter uma coleta de dados precisa e eficaz.
301: Moved Permanently
Se você receber um erro 301 (movido permanentemente), o recurso que você está procurando foi movido permanentemente. Isso geralmente acontece quando um site está passando por atualizações, como remodelação ou reorganização do conteúdo.
Se você encontrar esse erro, seu scraper precisará transferir suas referências de URL para o novo local provenientes dos cabeçalhos de resposta:
response_data = requests.get('http://example.com/old-page')
if response_data.status_code == 301:
new_redirect_url = response_data.headers['Location']
response_data = requests.get(new_redirect_url)
Neste código, você instrui seu scraper a obter o local de redirecionamento que vem do cabeçalho. Em seguida, ele acessa o conteúdo em seu novo local:

302: Found (redirecionamento temporário)
O código de status 302 Found (encontrado) indica que o recurso que você está tentando acessar foi movido temporariamente para outro URL. Nesse caso, a alteração não é permanente e prevê-se que o URL original volte a ser viável em algum momento. Isso geralmente acontece quando um site está em manutenção.
Ao fazer extração de dados da web, é importante configurar seu script para lidar com redirecionamentos automaticamente, garantindo que os URLs armazenados permaneçam inalterados. Embora muitas bibliotecas HTTP, como Python requests, lidem com redirecionamentos 302 automaticamente, é importante verificar se esse comportamento está alinhado com suas metas de coleta, especialmente quando é necessário preservar o método de solicitação original:

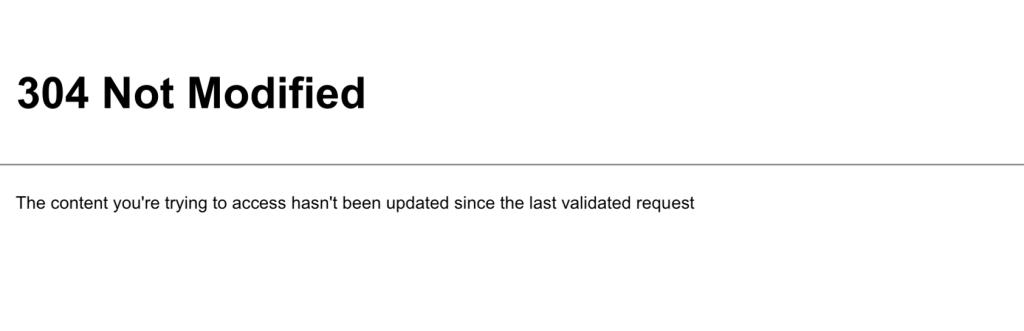
304: Not Modified
Se o conteúdo que você está tentando acessar não tiver sido atualizado desde a última solicitação validada, você receberá um erro 304 (não modificado). Esse erro ajuda a aumentar a eficiência das atividades de extração de dados da web, impedindo o download de dados desnecessários.
Se seu scraper acessar uma página que já foi baixada, os cabeçalhos da solicitação, como If-Modified-Since ou If-None-Match, podem ser usados para verificar se o conteúdo não foi alterado:
import requests
# Correct header format and Python syntax
headers = {'If-Modified-Since': 'Sat, Oct 29 2024 19:43:31 GMT'}
# Making a GET request to the server with the headers
response = requests.get('http://example.com/page', headers=headers)
# Checking if the status code returned is 304
if response.status_code == 304:
print("Content has not changed.")
Nesse código, você começa testando se o código de resposta é 304. Se for verdade, ele então gera Message Content has not changed(O conteúdo da mensagem não mudou) e você não precisa fazer nada:
307: Temporary Redirect
Um redirecionamento temporário, código de status 307, informa que o recurso que você está tentando acessar está temporariamente posicionado em outro URL. Nesse caso, o mesmo método HTTP e o mesmo corpo da solicitação original podem ser reutilizados com o URL redirecionado. Aqui é diferente do 302, em que o URL redirecionado pode usar um método e um corpo diferentes:
response = requests.post('http://examples.com/submit-form', data={'key': 'value'} )
if response.status_code == 307:
response = requests.post(response.headers['Location'], data={'key': 'value'})
Você deve manter a ordem ao redirecionar um rastreador da web. Isso ajuda a garantir uma coleta de dados confiável e eficaz, respeitando a estrutura e o sistema do servidor do site de destino. O código a seguir verifica se o status da resposta é 307; se for verdade, ele reenvia os mesmos dados no corpo para a nova Location (localização) especificada no cabeçalho da resposta:

Códigos 4xx: erros do lado do cliente
Os erros de cliente são indicados pela classe 4xx de códigos de status HTTP e geralmente resultam de um problema com a solicitação feita pelo cliente. Frequentemente, esses erros resultam na retificação dos parâmetros da solicitação ou no aprimoramento operacional dos mecanismos de autenticação.
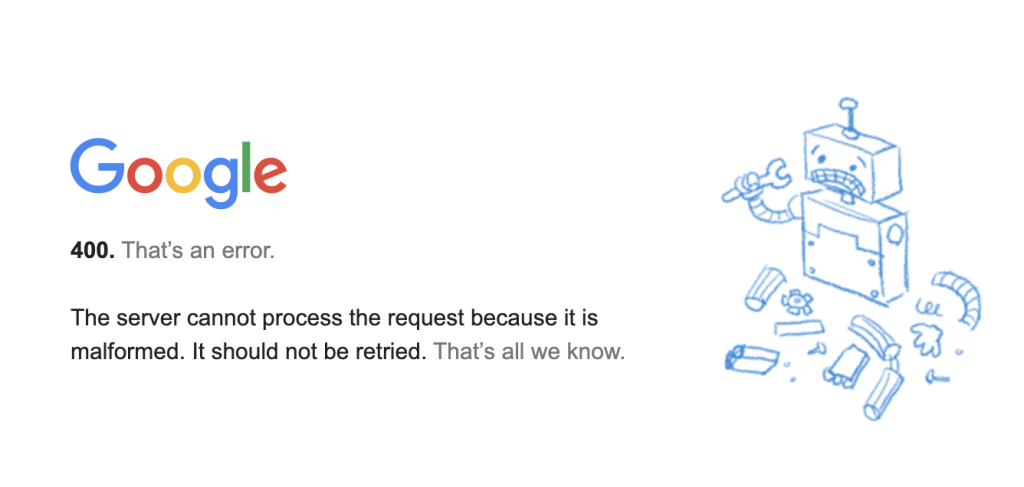
400: Bad Request
O erro 400 Bad Request (solicitação inválida) indica que o servidor não conseguiu entender a solicitação. Na extração de dados da web, isso geralmente acontece quando o cabeçalho da solicitação não está escrito corretamente ou faltam partes.
Por exemplo, se você enviar informações acidentalmente no formato errado (, por exemplo, enviar texto em vez de JSON), o servidor não conseguirá lidar com a solicitação e ela será rejeitada. Para resolver esse problema, você deve executar cuidadosamente a validação e garantir que a sintaxe da solicitação atenda às expectativas do servidor.
Na extração de dados da web, há várias etapas que você precisa concluir para verificar se suas solicitações atendem às expectativas do servidor. Inicialmente, você precisa ter certeza de que entende a estrutura do site de destino. Você pode usar as ferramentas do desenvolvedor do navegador para ajudá-lo a inspecionar elementos e descobrir como os dados estão formatados. Além disso, você deve implementar testes e tratamento de erros e garantir o uso de cabeçalhos adequados em suas solicitações:
401: Unauthorized
Um erro 401 Unauthorized (não autorizado) indica uma falha ou falta de autenticação necessária para acessar um recurso. Na extração de dados da web, isso geralmente acontece ao tentar acessar conteúdo autenticado. Por exemplo, acessar dados baseados em assinatura com credenciais incorretas aciona esse erro. Para evitar essa situação, certifique-se de incluir os cabeçalhos de autenticação corretos nas suas solicitações:

403: Forbidden
Um erro 403 Forbidden (proibido) significa que o servidor conseguiu entender a solicitação, mas se recusou a permitir que você acessasse o recurso. Essa é uma ocorrência comum ao fazer extração de dados da web de um site que tem controles de acesso rígidos. Muitas vezes, você encontrará esse erro ao entrar em uma parte proibida de um site. Por exemplo, se você estiver efetuando autenticação como usuário e estiver tentando acessar as postagens de outro usuário, não poderá fazer isso porque não tem permissão:

Se você receber um erro 403, verifique a autorização controlando suas chaves ou credenciais. Se a autorização não estiver disponível e você não tiver nenhuma credencial válida, é recomendável evitar copiar esse conteúdo para se adequar à política de acesso do site.
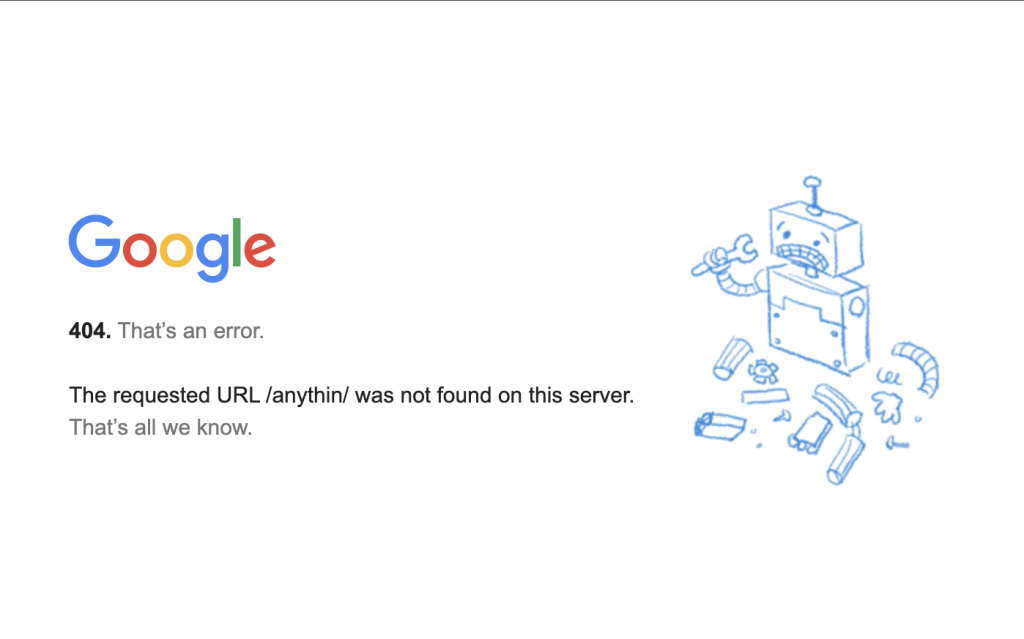
404: Not Found
Quando o servidor não consegue encontrar o recurso que está sendo solicitado, ele retorna o erro 404 Not Found (não encontrado).
Isso geralmente acontece quando os URLs usados na extração de dados da web são alterados ou quebrados, como quando a página de um produto é excluída ou sua URL é modificada sem redirecionamento ou atualizações.
Para resolver esse problema, verifique os URLs em seu script de extração de dados e atualize-os conforme necessário para se alinharem à estrutura atual do site:
É sempre recomendável lidar com qualquer erro 404 em seu código.
Se você estiver usando Python e o servidor não encontrou o recurso, você pode instruir seu código a passar o seguinte bloco de código para que seu código não pare quando esse erro acontecer:
import requests
# List of URLs to fetch
urls = [
"http://example.com/nonexistentpage.html", # This should result in 404
"http://example.com" # This should succeed
]
for url in urls:
try:
response = requests.get(url)
if response.status_code == 404:
print(f"Error 404: URL not found: {url}")
# Continue to the next URL in the list
continue
print(f"Successfully retrieved data from {url}")
print(response.text[:200]) # Print the first 200 characters of the response content
except requests.exceptions.RequestException as e:
print(f"An error occurred while fetching {url}: {e}")
continue # Continue to the next URL even if a request exception occurs
print("Finished processing all URLs.")
No código a seguir, você itera sobre a matriz de URLs e depois tenta buscar o conteúdo da página. Quando falha com um erro de 400, o código continua até a próxima URL na matriz.
407: Proxy Authentication Required
O erro 407 Proxy Authentication Required (autenticação de proxy necessária) é acionado quando o cliente precisa se autenticar no servidor proxy para que a solicitação possa prosseguir. Esse erro geralmente ocorre durante a extração de dados da web, quando o servidor proxy precisa de autenticação. É diferente de um erro 401 quando a autenticação é necessária para acessar dados relacionados ao site de destino.
Por exemplo, se você encontrar esse erro ao usar um proxy privado para acessar dados de um site de destino, você não está autenticado. Para resolver esse problema, você deve adicionar detalhes de autenticação de proxy válidos em suas solicitações:

408: Request Timeout
Um código de status 408 Request Timeout (tempo limite de solicitação) indica que o servidor esperou muito tempo pela solicitação. Esse erro pode ocorrer quando o scraper está muito lento ou se o servidor está sobrecarregado, especialmente durante os horários de pico.
Quando o tempo de solicitação é otimizado e as novas tentativas são implementadas com mecanismos de recuo exponencial, esse problema pode ser minimizado, pois o servidor tem tempo suficiente para responder:

429: Too Many Requests
O erro 429 Too Many Requests (pedidos em excesso) é gerado quando um usuário envia muitas solicitações em um curto espaço de tempo. Essa é uma ocorrência comum quando os limites da taxa de extração de dados da web em um site são excedidos. Por exemplo, se você consultar um site com frequência, o limite de taxa será ativado e você será impedido de coletar dados.
Certifique-se de respeitar os limites de taxa da API do site de destino e aplicar algumas das melhores práticas de extração de dados, como atrasar as solicitações, o que pode evitar esse problema e manter o acesso aos recursos necessários:

Códigos 5xx: problemas do lado do servidor
Problemas no servidor são indicados por códigos de status HTTP da série 5xx e se referem à incapacidade do servidor de atender às solicitações devido a problemas internos. Você deve entender esses erros na extração de dados da web, pois eles geralmente exigem uma abordagem distinta em comparação com o tratamento de erros do lado do cliente.
500: Internal Server Error
Um 500 Internal Server Error (erro interno do servidor) é uma resposta genérica que informa que ocorreu uma situação anormal no servidor que não permitiu que ele concluísse a solicitação específica. Esse problema não vem de nenhum erro cometido pelo cliente; ao contrário, significa que o problema está dentro do próprio servidor.
Por exemplo, ao coletar dados, esse erro pode ocorrer ao tentar acessar uma página no servidor. Para resolver o problema, você pode tentar novamente mais tarde ou planejar seus projetos de web scraping para que ocorram quando não for o horário de pico e o servidor não estiver carregado:

501: Not Implemented
O erro 501 Not Implemented (não implementado) ocorre quando o servidor não reconhece o método de solicitação ou não conclui esse método. Como você normalmente testa os métodos do seu rastreador com antecedência, esse erro raramente acontece na extração de dados da web, mas pode ocorrer se você estiver usando métodos HTTP atípicos.
Por exemplo, se seu scraper estiver configurado para usar métodos que não são suportados pelo servidor (por exemplo, PUT ou DELETE) e esses métodos forem necessários para suas funções de extração de dados da web, você receberá um erro 501. Para evitar esse problema, certifique-se de que, se seus scripts de extração de dados usarem métodos HTTP, esses métodos sejam necessários em todos os lugares:

502: Bad Gateway
O erro 502 Bad Gateway indica que, apesar de atuar como gateway ou proxy, o servidor recebeu uma resposta inadequada do servidor de destino e foi acessado para atender à solicitação. Isso indica que houve um problema de comunicação com os servidores intermediários.
Durante a extração de dados da web, o erro 502 pode ocorrer quando o servidor proxy que você está usando não consegue obter uma resposta apropriada do servidor de destino. Para corrigir esse erro, verifique se a integridade e a configuração do seu servidor proxy estão funcionando e se podem se comunicar com os servidores de destino. Você pode monitorar o uso da CPU, da memória e da largura de banda da rede no seu servidor proxy. Você também pode verificar os registros de erros do servidor proxy, o que pode indicar se há problemas com o tratamento de suas solicitações:

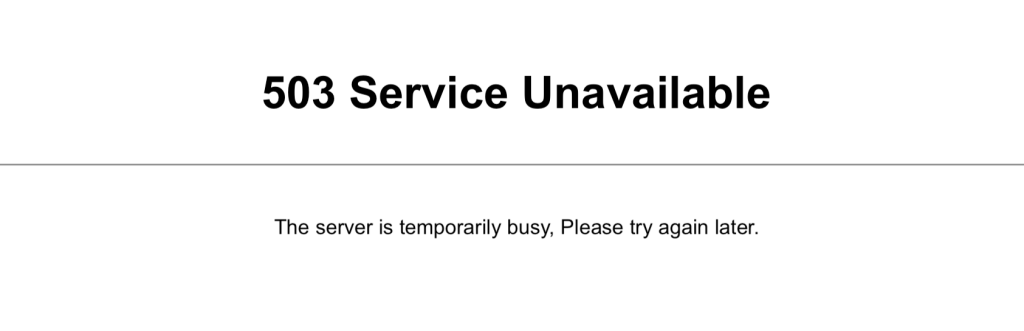
503: Service Unavailable
O erro 503 Service Unavailable (serviço indisponível) indica que o servidor está ocupado e não pode atender à solicitação. Isso pode ocorrer devido à manutenção ou sobrecarga do servidor.
Ao fazer extração de dados da web, você geralmente encontrará esse erro ao tentar acessar sites que não estão acessíveis durante a manutenção ou o horário de pico. Ao contrário do erro 500, que indica um problema no servidor, o erro 503 indica que o servidor está operacional, mas indisponível no momento.
Para evitar esse erro, você deve implementar uma estratégia de repetição que use recuo exponencial. Os intervalos de recuo devem aumentar à medida que as solicitações forem repetidas. Como resultado, as solicitações não devem causar saturação do servidor durante o tempo de inatividade:
504: Gateway Timeout
O erro 504 Gateway Timeout (tempo limite do gateway) ocorre quando o servidor que atua como gateway ou proxy não consegue obter uma resposta do servidor upstream a tempo. Esse erro é um problema de tempo limite e uma variante do erro 502.
Quando se trata de extração de dados da web, esse erro geralmente acontece quando a resposta do servidor de destino ao seu proxy é muito lenta (ou seja, demorou mais de 120 segundos). Para resolver isso, você pode ajustar as configurações de tempo limite do seu scraper para aderir a tempos de espera mais longos ou verificar a integridade e a capacidade de resposta do seu servidor proxy:

505: HTTP Version Not Supported
O erro 505 HTTP Version Not Supported (Versão HTTP não suportada) ocorre quando o servidor não reconhece a versão do protocolo HTTP especificada na solicitação. Isso é incomum na extração de dados da web, mas pode acontecer se o servidor de destino estiver configurado para oferecer suporte apenas a determinadas versões do protocolo HTTP. Por exemplo, se suas solicitações de extração de dados chegarem com uma versão muito recente ou muito antiga, o servidor não as aceitará.
Para evitar esse erro, certifique-se de que seus cabeçalhos de solicitação HTTP indiquem uma versão aceitável para o servidor de destino, provavelmente HTTP/1.1 ou HTTP/2, que são as mais frequentemente suportadas:
Dicas rápidas para evitar erros comuns de proxy
Erros de proxy podem ser frustrantes, mas muitos deles podem ser contornados com a implementação de algumas estratégias específicas no seu web scraper.
Tente novamente a solicitação
Muitos problemas de proxy são causados por problemas de curto prazo, como breves interrupções de rede ou pequenas falhas no servidor. Tentar novamente a solicitação pode contornar o problema se a situação tiver sido resolvida naturalmente.
Veja como você pode implementar novas tentativas em seu script de extração de dados usando a biblioteca requests do Python e a lógica de repetição urllib3:
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def requests_retry_session(
retries=3,
backoff_factor=0.3,
status_forcelist=(500, 502, 503, 504),
session=None,
):
session = session or requests.Session()
retry = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
s = requests_retry_session()
try:
response = s.get('http://example.com', proxies={"http": "http://proxy_address:port"})
print(response.text)
except requests.exceptions.HTTPError as e:
print('HTTPError:', e)
Esse código define um mecanismo de novas tentativas com um fator de recuo, o que significa que, se uma solicitação falhar, você repetirá a mesma solicitação até três vezes, esperando um pouco mais a cada vez antes da próxima tentativa.
Verifique as configurações de proxy
Configurações incorretas do proxy podem levar a vários erros. Por exemplo, esses erros podem ocorrer se você inserir uma porta de proxy, endereço IP ou informações de autenticação incorretas. Certifique-se de verificar se suas configurações estão corretas de acordo com as necessidades da sua rede para que as solicitações possam chegar ao destino.
Consultar documentação e suporte
Se você tiver algum problema ao utilizar um serviço de proxy ou uma biblioteca, sempre consulte a documentação oficial como sua primeira linha de defesa. Se você não conseguir encontrar o que está procurando na documentação, verifique se o serviço ou a biblioteca tem um canal no Slack ou no Discord no qual você possa participar. Por fim, você sempre pode abrir um chamado no canal de suporte ou enviar um e-mail com os detalhes e as perguntas para as quais deseja respostas.
Conclusão
Este artigo ensinou tudo sobre vários códigos de erro de proxy e seus significados, ajudando você a identificar cada erro e solucionar problemas durante a extração de dados da web. Você também aprendeu algumas dicas úteis para evitar que erros comuns ocorram em primeiro lugar.
Se você está enfrentando erros de proxy, considere utilizar os serviços de proxy da Bright Data. Nossos proxies podem ajudar a reduzir a ocorrência de erros e resultar em um processo de coleta de dados mais eficiente. Seja você um especialista ou um novato, o conjunto de ferramentas de proxy Bright Data pode ajudá-lo a fortalecer suas habilidades de web scraping.





