

O web scraping — uma técnica de coleta de dados de sites da web — muitas vezes é prejudicado por vários obstáculos, incluindo bloqueios de IP, restrição geográfica e questões de privacidade. Felizmente, os servidores proxy podem ajudar você a enfrentar esses desafios. Eles servem como intermediários entre seu computador e a internet, processando solicitações com seus próprios endereços IP. Essa funcionalidade não só ajuda a evitar restrições e bloqueios relacionados a IP, mas também facilita o acesso a conteúdo geograficamente restrito. Além disso, os servidores proxy são fundamentais para manter o anonimato durante o web scraping, protegendo sua privacidade.
Utilizar servidores proxy também pode melhorar o desempenho e a confiabilidade dos seus esforços de web scraping. Ao distribuir solicitações entre vários servidores, eles garantem que nenhum servidor individual suporte uma carga excessiva, otimizando o processo.
Neste tutorial, você aprenderá a usar um servidor proxy em Node.js para seus projetos de web scraping.
Pré-requisitos
Antes de começar este tutorial, é recomendado que você tenha familiaridade com JavaScript e Node.js. Se o Node.js ainda não estiver instalado no seu computador, você precisará instalá-lo agora.
Você também precisa de um editor de texto adequado. Há várias opções disponíveis, como o Sublime Text. Este tutorial usa o Visual Studio Code (VS Code). Ele é fácil de usar e repleto de recursos que facilitam a programação.
Para começar, crie um novo diretório chamado web-scraping-proxy e inicialize seu projeto Node.js. Abra seu terminal ou shell e navegue até o novo diretório usando os comandos a seguir:
cd web-scraping-proxy
npm init -y
Depois disso, você precisará instalar alguns pacotes de Node.js para processar solicitações HTTP e analisar HTML.
Certifique-se de que está no diretório do seu projeto e, então, execute o seguinte:
npm install axios playwright puppeteer http-proxy-agent
npx playwright install
O Axios é usado para fazer solicitações HTTP para recuperar conteúdo da web. A Playwright e a Puppeteer automatizam as interações com o navegador, o que é essencial para coletar dados de sites dinâmicos. A Playwright suporta vários navegadores, e a Puppeteer é focada em Chrome ou Chromium. A biblioteca http-proxy-agent será usada para criar um agente de proxy para as solicitações HTTP.
A npx playwright install é necessária para instalar os drivers necessários que a biblioteca Playwright usará.
Depois de concluir esses passos, você estará pronto para mergulhar no mundo do web scraping com o Node.js.
Configure um proxy local para web scraping
Um dos primeiros passos cruciais em web scraping é estabelecer um servidor proxy. Neste tutorial, você usará a ferramenta de código aberto mitmproxy.
Para começar, acesse a página de download do mitmproxy e baixe a versão 10.1.6 específica para o seu sistema operacional. Se precisar de orientação durante a instalação, o guia de instalação do mitmproxy é um recurso útil.
Depois de instalado, inicie o mitmproxy digitando o seguinte comando no seu terminal:
mitmproxy
Esse comando abre uma janela no seu terminal que serve como interface para o mitmproxy:

Para garantir que seu proxy esteja configurado corretamente, tente fazer um teste. Abra uma nova janela do terminal e execute o seguinte comando:
curl --proxy http://localhost:8080 "http://wttr.in/Paris?0"
Esse comando busca o boletim meteorológico de Paris. Seu resultado deve ficar assim:
Weather report: Paris
Overcast
.--. -2(-6) °C
.-( ). ↙ 11 km/h
(___.__)__) 10 km
0.0 mm
De volta à janela do mitmproxy, você notará que ela capturou a solicitação, indicando que seu proxy local está funcionando corretamente:

Implemente um proxy para web scraping em Node.js
Agora é hora de passar para os aspectos práticos do web scraping com o Node.js. Nesta seção, você escreverá um script que coleta dados de um site enviando solicitações através do servidor proxy local.
Colete dados de um site usando o método fetch
Crie um novo arquivo chamado fetchScraping.js no diretório raiz do seu projeto. Esse arquivo conterá o código para extrair o conteúdo de um site, que neste caso é https://toscrape.com/.
Em seu fetchScraping.js, insira o seguinte código JavaScript. Esse script usa o método fetch para enviar solicitações através do seu servidor proxy:
const fetch = require("node-fetch");
const HttpProxyAgent = require("http-proxy-agent");
async function fetchData(url) {
try {
const proxyAgent = new HttpProxyAgent.HttpProxyAgent(
"http://localhost:8080"
);
const response = await fetch(url, { agent: proxyAgent });
const data = await response.text();
console.log(data); // Outputs the fetched data
} catch (error) {
console.error("Error fetching data:", error);
}
}
fetchData("http://toscrape.com/");
Esse trecho de código define uma função fetchData assíncrona que pega uma URL e envia uma solicitação a essa URL usando fetch enquanto a direciona pelo proxy local. Depois, ele imprime os dados da resposta.
Para executar seu script de web scraping, abra o terminal ou shell e acesse o diretório raiz do seu projeto, onde seu arquivo fetchScraping.js está localizado. Execute o script usando este comando:
node fetchScraping.js
Você deve ver o seguinte resultado no terminal:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Esse resultado é o conteúdo HTML da página http://toscrape.com. A exibição bem-sucedida desses dados indica que seu script de web scraping, roteado através do proxy local, está funcionando corretamente.
Agora, volte para a janela do mitmproxy e você verá a solicitação sendo registrada, o que significa que sua solicitação passou pelo proxy local:

Colete dados de um site usando a Playwright
Comparada ao fetch, a Playwright é uma ferramenta avançada que permite interações mais dinâmicas com páginas da web. Para usá-la, você precisa criar um novo arquivo chamado playwrightScraping.js no seu projeto. Nesse arquivo, insira o seguinte código JavaScript:
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
proxy: {
server: "http://localhost:8080",
},
});
const page = await browser.newPage();
await page.goto("http://toscrape.com/");
// Extract and log the entire HTML content
const content = await page.content();
console.log(content);
await browser.close();
})();
Esse código usa a Playwright para iniciar uma instância do navegador Chromium configurada para usar seu servidor proxy local. Ele, então, abre uma nova página no navegador, acessa http://toscrape.come aguarda o carregamento da página. Depois de coletar os dados necessários, o navegador é fechado.
Para executar esse script, certifique-se de que você está no diretório que contém o playwrightScraping.js. Abra seu terminal ou shell e execute o script usando o seguinte:
node playwrightScraping.js
Quando você executa o script, a Playwright inicia um navegador Chromium, acessa a URL especificada e executa todos os comandos adicionais de scraping que você tiver incluído. Esse processo usa o servidor proxy local, ajudando a evitar a exposição do seu endereço IP e a contornar possíveis restrições.
O resultado esperado deve ser semelhante ao anterior:
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Da mesma forma que antes, você deve conseguir ver sua solicitação sendo registrada na janela do mitmproxy.
Colete dados de um site usando a Puppeteer
Agora colete os dados um site usando a Puppeteer. A Puppeteer é uma ferramenta poderosa que fornece um alto nível de controle sobre um navegador headless (sem interface gráfica) baseado em Chrome ou Chromium. Esse método é particularmente útil para coletar dados de sites dinâmicos que exigem renderização de JavaScript.
Para começar, crie um novo arquivo em seu projeto chamado puppeteerScraping.js. Esse arquivo conterá o código da Puppeteer para coletar dados de um site usando o servidor proxy para solicitações.
Abra o arquivo puppeteerScraping.js recém-criado e insira o seguinte código JavaScript:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
args: ['--proxy-server=http://localhost:8080']
});
const page = await browser.newPage();
await page.goto('http://toscrape.com/');
const content = await page.content();
console.log(content); // Outputs the page HTML
await browser.close();
})();
Nesse código, você inicializa a Puppeteer para abrir um navegador headless, especificando que ele deve usar seu servidor proxy local. O navegador abre uma nova página, acessa http://toscrape.com e recupera o conteúdo HTML da página. Depois que o conteúdo é registrado no console, a sessão do navegador é fechada.
Para executar seu script, acesse a pasta que contém o puppeteerScraping.js em seu terminal ou shell. Execute o script usando o seguinte comando:
node puppeteerScraping.js
Depois de executar o script, a Puppeteer abre a URL http://toscrape.com/ usando o servidor proxy. Você deve ver o conteúdo HTML da página impresso no seu terminal. Isso indica que seu script da Puppeteer está coletando dados da página da web corretamente através do proxy local.
O resultado esperado deve ser semelhante aos anteriores, e você deve ver sua solicitação sendo registrada na janela do mitmproxy :
…output omitted…
<div class="row">
<div class="col-md-1"></div>
<div class="col-md-10">
<h2>Books</h2>
<p>A <a href="http://books.toscrape.com">fictional bookstore</a> that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: <a href="http://books.toscrape.com">books.toscrape.com</a></p>
<div class="col-md-6">
<a href="http://books.toscrape.com"><img src="./img/books.png" class="img-thumbnail"></a>
</div>
<div class="col-md-6">
<table class="table table-hover">
<tr><th colspan="2">Details</th></tr>
<tr><td>Amount of items </td><td>1000</td></tr>
<tr><td>Pagination </td><td>✔</td></tr>
<tr><td>Items per page </td><td>max 20</td></tr>
<tr><td>Requires JavaScript </td><td>✘</td></tr>
</table>
</div>
</div>
</div>
…output omitted…
Uma alternativa melhor: o servidor proxy da Bright Data
Se deseja melhorar sua capacidade para fazer web scraping, considere usar a Bright Data. O servidor proxy da Bright Data oferece uma solução avançada para gerenciar suas solicitações da web.
A Bright Data oferece vários servidores proxy, como proxies residenciais, de provedor de internet, de data center e móveis, que permitem a você acessar qualquer site em diferentes localizações geográficas. Isso permite que você emule diferentes agentes de usuário e mantenha o anonimato.
A Bright Data também oferece rodízio de proxies, que aumenta a eficiência e o anonimato das suas atividades de web scraping trocando automaticamente entre diferentes proxies para evitar que seu IP seja bloqueado.
Além disso, você pode usar o Scraping Browser da Bright Data, que é um navegador automatizado com funções integradas de desbloqueio para mecanismos como CAPTCHA, cookies e impressão digital do navegador. Você também pode utilizar o Web Unlocker da Bright Data, que vem com algoritmos de aprendizado de máquina para contornar qualquer bloqueio dos sites abordados e permite que você colete dados sem ser bloqueado.
Implemente o proxy da Bright Data em um projeto de Node.js
Para integrar um proxy da Bright Data ao seu projeto Node.js, você precisa se cadastrar para um teste gratuito. Quando sua conta estiver ativa, faça login, acesse Proxies e Infraestrutura de Scraping e selecione Proxies Residenciais para adicionar um novo proxy:

Mantenha as configurações padrão e finalize a criação do seu proxy residencial:

Depois de criado, anote as credenciais do proxy, incluindo host, porta, nome de usuário e senha. Você precisará delas no próximo passo:
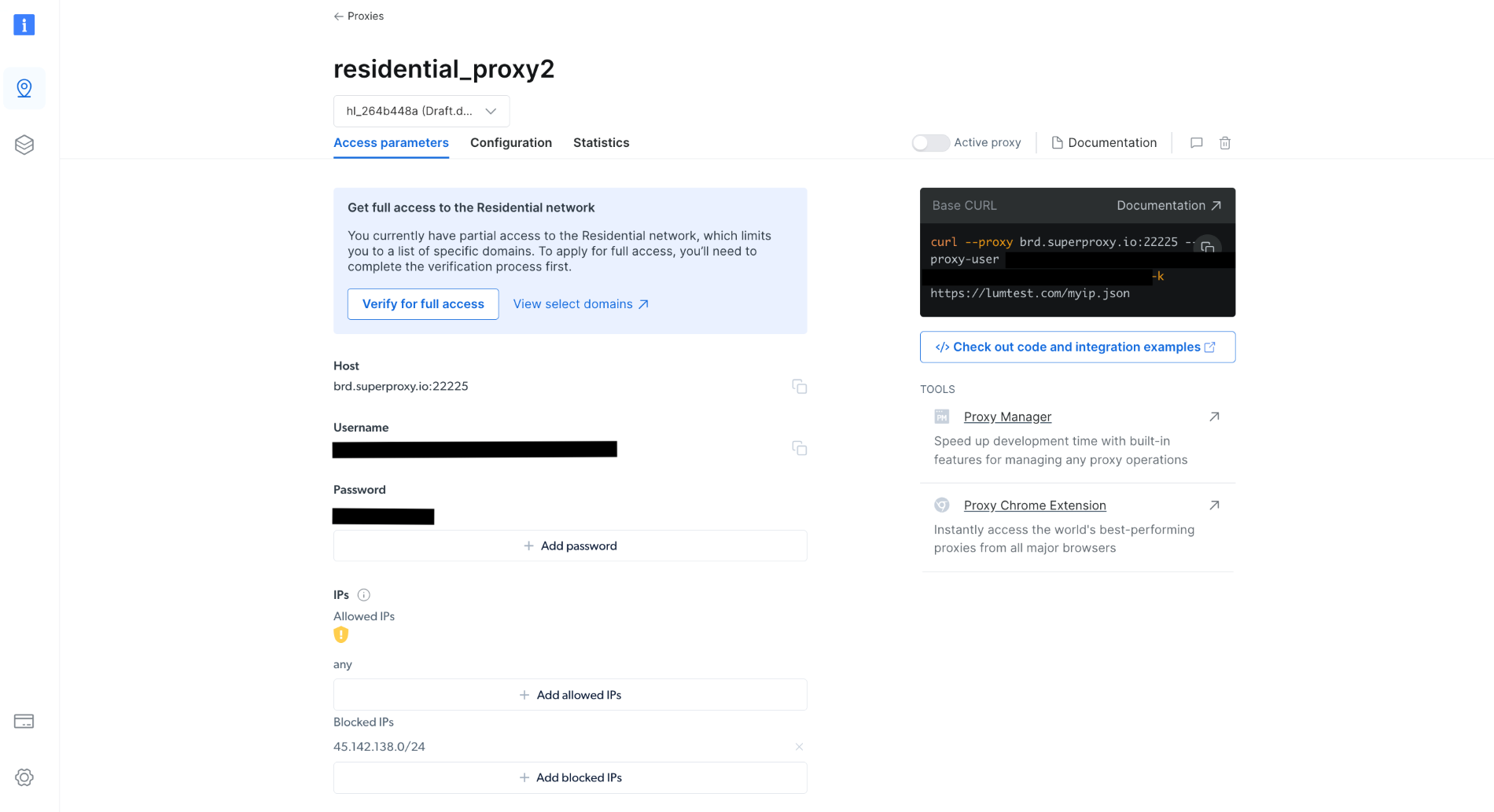
No seu projeto, crie um arquivo scrapingWithBrightData.js e adicione o trecho a seguir, lembrando-se de substituir o texto do espaço reservado pelas suas credenciais no proxy da Bright Data:
const axios = require('axios');
async function fetchDataWithBrightData(url) {
const proxyOptions = {
proxy: {
host: 'YOUR_BRIGHTDATA_PROXY_HOST',
port: YOUR_BRIGHTDATA_PROXY_PORT,
auth: {
username: 'YOUR_BRIGHTDATA_USERNAME',
password: 'YOUR_BRIGHTDATA_PASSWORD'
}
}
};
try {
const response = await axios.get(url, proxyOptions);
console.log(response.data); // Outputs the fetched data
} catch (error) {
console.error('Error:', error);
}
}
fetchDataWithBrightData('http://lumtest.com/myip.json');
Esse script configura o Axios para rotear solicitações HTTP através do seu proxy da Bright Data. Ele busca dados de uma URL especificada usando essa configuração de proxy. Neste exemplo, você usará http://lumtest.com/myip.json para ver as diferentes fontes de servidores proxy com base na sua configuração na Bright Data.
Para executar seu script, acesse a pasta que contém scrapingWithBrightData.js em seu terminal ou shell. Em seguida, execute o script usando o seguinte comando:
node scrapingWithBrightData.js
Depois de executar o comando, você deve obter a localização do seu endereço IP enviado ao console, que está relacionado principalmente ao servidor proxy da Bright Data.
O resultado esperado é parecido com o seguinte:
{
ip: '108.53.191.230',
country: 'US',
asn: { asnum: 701, org_name: 'UUNET' },
geo: {
city: 'Jersey City',
region: 'NJ',
region_name: 'New Jersey',
postal_code: '07302',
latitude: 40.7182,
longitude: -74.0476,
tz: 'America/New_York',
lum_city: 'jerseycity',
lum_region: 'nj'
}
}
Agora, se executar o script novamente com o arquivo scrapingWithBrightData.js, você notará que um endereço IP de outro local está sendo usado pelo servidor proxy da Bright Data. Isso confirma que a Bright Data usa diferentes locais e IPs cada vez que você executa seu script de web scraping, o que permite contornar qualquer restrição ou bloqueio de IP dos sites abordados.
Seu resultado deve ficar assim:
{
ip: '93.85.111.202',
country: 'BY',
asn: {
asnum: 6697,
org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'
},
geo: {
city: 'Orsha',
region: 'VI',
region_name: 'Vitebsk',
postal_code: '211030',
latitude: 54.5081,
longitude: 30.4172,
tz: 'Europe/Minsk',
lum_city: 'orsha',
lum_region: 'vi'
}
}
A interface e as configurações simples da Bright Data facilitam para qualquer pessoa, inclusive iniciantes, o uso eficaz de seus poderosos recursos de gerenciamento de proxy.
Conclusão
Neste artigo, você aprendeu a usar proxies com o Node.js. Sem soluções adequadas de gerenciamento de proxy, como a Bright Data, você pode encontrar desafios, como bloqueios de IP e acesso limitado aos sites abordados, o que pode atrapalhar seus esforços de scraping. Você também aprendeu como é fácil usar os proxies da Data Bright para melhorar sua capacidade de web scraping. Esses servidores não só contribuem para o seu processo de coleta de dados com robustez e eficiência, mas também proporcionam a versatilidade necessária para diferentes cenários de scraping.
Ao colocar essas habilidades em prática, lembre-se da importância de operar em conformidade com os termos do site e das leis de privacidade de dados. É essencial coletar dados com responsabilidade, respeitando as regras estabelecidas pelos sites. Com o conhecimento que você adquiriu, especialmente os recursos oferecidos pelos proxies da Bright Data, você está bem-preparado para um web scraping ético e bem-sucedido. Bom scraping!
Não é necessário cartão de crédito
Todo o código deste tutorial está disponível neste repositório do GitHub.


